
TransformerFAM
...大约 2 分钟
基础信息
1. 研究问题
这篇论文研究了Transformer模型在处理长序列输入时面临的二次注意力复杂度问题,这限制了它们对无限长输入的处理能力。
2. 解决模型及架构
- 模型名称: Feedback Attention Memory (FAM)
- 架构: TransformerFAM通过一个反馈循环设计,使网络能够关注自身的潜在表示,从而促进Transformer内部工作记忆的产生。
- 模块: 使用了标准的Transformer层,并引入了Block Sliding Window Attention (BSWA)作为处理长上下文输入的两种主要方法之一。
- 预训练模型: 是的,TransformerFAM能够无缝集成与预训练模型,实验中使用了1B, 8B, 和 24B的Flan-PaLM LLMs进行微调。
- 预训练模型来源: Flan-PaLM是构建在预训练PaLM模型之上的,通过指令微调进行训练。
3. 解决结果与验证
- 结果: TransformerFAM在长上下文任务上显著提高了Transformer的性能。
- 数据集: 测试和验证了多个长上下文任务,包括但不限于Isabelle、NarrativeQA、PG-19、ScrollsQasper、ScrollsQuality和XLSum。
- 验证指标: 使用了准确率、ROUGE-L等指标进行评估。
- 对比方法: 与标准的Transformer模型、Transformer with Sliding Window Attention (SWA)、Block Sliding Window Attention (BSWA)等方法进行了对比。
4. 核心创新点
- 工作记忆: 引入了工作记忆的概念,通过反馈循环机制使Transformer能够维持长期依赖关系。
- 无需额外权重: TransformerFAM不需要额外的权重,可以重用预训练的模型权重。
- 计算复杂度: 在推理过程中,TransformerFAM具有线性的计算复杂度O(L),其中L是处理的token长度。
5. 未解决问题
论文中提到了尽管TransformerFAM在长上下文任务上取得了进步,但深度学习中的记忆问题仍然是一个开放性挑战,需要进一步的研究来解决。此外,推理和记忆的转移至长期记忆也是未来研究的方向。
笔记
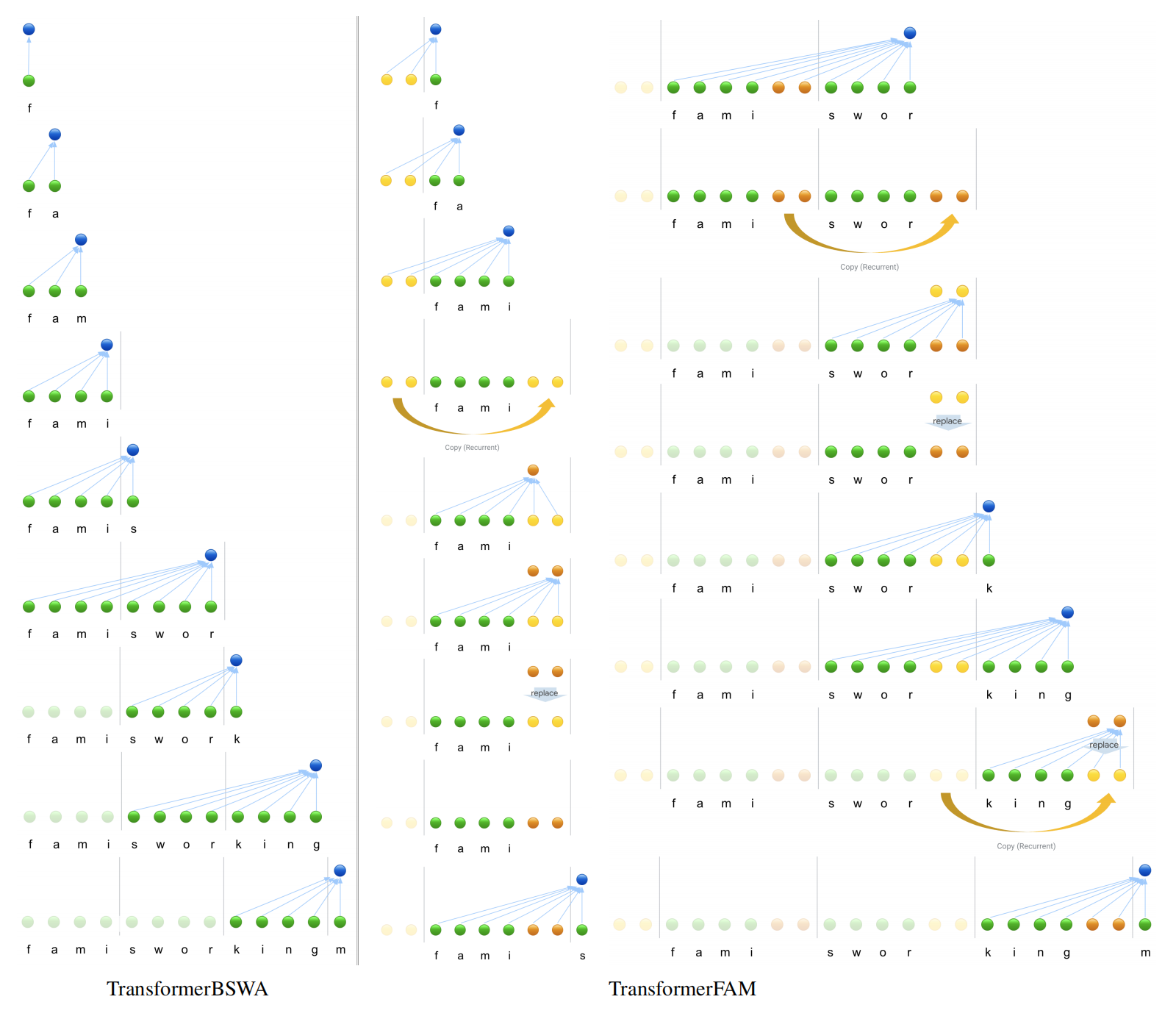
看了半天没看懂咋做的,然后看到了附录里的这张图,秒懂,这张图为啥要放附录里!……这篇论文关于将Transformer的推理降到O(n)的方式是类似于滑动窗口(Block Sliding Window Attention, BSWA)的操作,但做的改进是添加了一部分长期记忆(称之为Feedback Loop),其窗口内一部分是短期记忆,一部分是长期记忆,进行了一定的权衡。目前在将推理时间复杂度降低到一次时间复杂度的方法大抵如此,Mamba也是类似于通过了一种记忆模块,随着时间的推移逐步遗忘之前的元素。