
BEV
BEVFormer
PipeLine流程
其实和大多数的算法流程一样,BEVFormer的pipeline流程如下:
- 使用Backbone和Neck(ResNet-101-DCN + FPN)提取环视图像的多尺度特征。
- Encoder模块(包括Temporal Self-Attention模块和Spatial Cross-Attention模块),通过论文提出的方法将环视图像特征转换为BEV特征。
- 类似于Deformable DETR的Decoder模块,完成3D目标检测的分类和定位任务。
- 正负样本的定义采用了Transformer中常用的匈牙利匹配算法,使用Focal Loss + L1 Loss作为总损失,并最小化该损失。
- 损失的计算使用Focal Loss分类损失和L1 Loss回归损失,并进行反向传播和更新网络模型参数。
输入数据格式
对于BEVFormer网络模型,输入数据是一个6维张量:(bs,queue,cam,C,H,W)。其中:
- bs表示batch size大小;
- queue表示连续帧的数量。由于BEVFormer采用了时序信息的思想(我认为加入时序信息后,可以一定程度上缓解遮挡问题),因此输入到网络模型中的数据要包括之前几帧的数据,而不仅仅是当前帧的数据;
- cam表示每帧中包含的图像数量。在nuScenes数据集中,一辆车通常带有六个环视相机传感器,可以实现360度全场景的覆盖,因此一帧会包含六张环视图片;
- C,H,W分别表示图片的通道数、高度和宽度。
网络特征提取
网络特征提取的目的是将每一帧对应的六张环视图像的特征提取出来,便于后续转换到 BEV 特征空间,生成 BEV 特征,在特征提取过程中,tensor流的变换情况如下:
# 输入图片信息 tensor: (bs, queue, cam, c, h, w)
# 通过 for loop 方式一次获取单帧对应的六张环视图像
# 送入到 Backbone + Neck 网络提取多尺度的图像特征
for idx in range(tensor.size(1) - 1): # 利用除当前帧之外的所有帧迭代计算 `prev_bev` 特征
single_frame = tensor[:, idx, :] # (bs, cam, c, h, w)
# 将 bs * cam 看作是 batch size,将原张量 reshape 成 4 维的张量
# 待 Backbone + Neck 网络提取多尺度特征后,再把 bs * cam 的维度再拆成 bs,cam
single_frame = single_frame.reshape(bs * cam, c, h, w)
feats = Backbone(FPN(single_frame))
""" feats 是一个多尺度的特征列表 """
[0]: (bs, cam, 256, h / 8, w / 8)
[1]: (bs, cam, 256, h / 16, w / 16)
[2]: (bs, cam, 256, h / 32, w / 32)
[3]: (bs, cam, 256, h / 64, w / 64)
BEV 特征产生
生成 BEV 特征的过程中,最核心的部分是论文中提出的 Encoder 模块,其中包括 Spatial Cross-Attention 和 Temporal Self-Attention。在这两个模块中,都使用了一个非常关键的组件:多尺度可变形注意力模块。这个模块将 Transformer 的全局注意力变为局部注意力,以减少训练时间并提高 Transformer 的收敛速度。(该思想最早出现在 Deformable DETR 中)
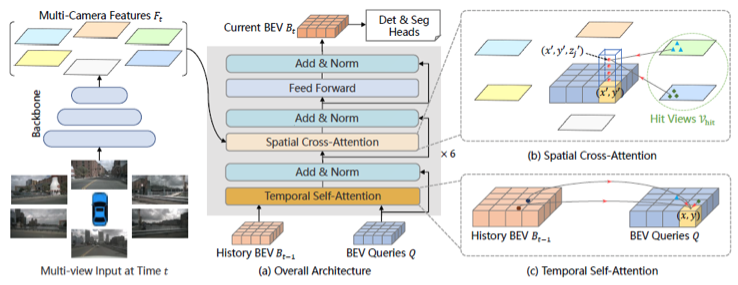
Temporal Self-Attention
作用是将时序信息(如插图中的历史 BEV)与当前时刻的 BEV Query 进行融合,以提高 BEV Query 的建模能力。
对于 Temporal Self-Attention 模块而言,需要 bev_query、bev_pos、prev_bev、ref_point、value等参数。
- 参数 bev_query:一个完全 learnable parameter,通过 nn.Embedding() 函数得到,形状 shape = (200 * 200,256);200,200 分别代表 BEV 特征平面的长和宽;
- 参数 bev_pose:感觉也是一个完全 learnable parameter,与 2D 检测中常见的正余弦编码方式不同,感觉依旧是把不同的 grid 位置映射到一个高维的向量空间,shape = (bs,256,200,200)。
- 参数 ref_point:这个参数根据当前 Temporal Self-Attention 模块是否有 prev_bev 特征输入而言,会对应不同的情况,之所以会出现不同,是考虑到了前后时刻 BEV 特征存在特征不对齐的问题,BEV 特征不对齐主要体现在车自身不断运动以及车周围物体也在一定范围内运动。对于 Temporal Self-Attention 模块没有输入 prev_bev(第一帧没有前一时刻的 BEV 特征)的情况,其 ref_point = ref_2d;对于存在输入 prev_bev 的情况,其 ref_point = ref_2d + shift;
- 参数 value:对应着bev_query去查询的特征;对于 Temporal Self-Attention 模块输入包含 prev_bev时,
value = [prev_bev,bev_query],对应的参考点ref_point = [ref_2d + shift,ref_2d];如果输入不包含 prev_bev时,value = [bev_query,bev_query],对应的参考点ref_point = [ref_2d,ref_2d]。
输出bev query:
""" 各个参数的 shape 情况
1. value: (2,40000,8,32)
# 2: 代表前一时刻的 BEV 特征和后一时刻的 BEV 特征,两个特征在计算的过程中是互不干扰的,
# 40000: 代表 bev_query 200 * 200 空间大小的每个位置
# 8: 代表8个头,# 32: 每个头表示为 32 维的特征
2. spatial_shapes: (200, 200) # 方便将归一化的 sampling_locations 反归一化
3. level_start_index: 0 # BEV 特征只有一层
4. sampling_locations: (2, 40000, 8, 1, 4, 2)
5. attention_weights: (2, 40000, 8, 1, 4)
6. output: (2, 40000, 8, 32)
"""
output = MultiScaleDeformableAttnFunction.apply(value, spatial_shapes, level_start_index, sampling_locations,attention_weights, self.im2col_step)
""" 最后将前一时刻的 bev_query 与当前时刻的 bev_query 做平均
output = output.permute(1, 2, 0)
output = (output[..., :bs] + output[..., bs:])/self.num_bev_queue
Spatial Cross-Attention
作用是利用 Temporal Self-Attention 模块输出的 bev_query,对主干网络和 Neck 网络提取到的多尺度环视图像特征进行查询,生成 BEV 空间下的 BEV Embedding 特征。
对于 Spatial Cross-Attention 模块而言,与 Temporal Self-Attention 模块需要的参数很类似,但是并不需要 bev_pos 参数,只需要 bev_query、ref_point、value(就是 concat 到一起的多尺度特征);
- 参数bev_query:bev_query参数来自于 Temporal Self-Attention 模块的输出;
- 参数queries_rebatch:之前也有提到,并不是 BEV 坐标系下的每个三维坐标都会映射到环视相机的所有图像上,而只会映射到其中的某几张图片上,所以使用所有来自 Temporal Self-Attention 模块的所有bev_query会消耗很大的计算量,所以这里是对bev_query进行了重新的整合。
- 参数value:对于 Transformer 而言,由于其本身是处理文本序列的模型,而文本序列都是一组组一维的数据,所以需要将前面提取的多尺度特征做 flatten() 处理,并将所有层的特征汇聚到一起,方便之后做查询;
""" 首先将多尺度的特征每一层都进行 flatten() """
for lvl, feat in enumerate(mlvl_feats):
bs, num_cam, c, h, w = feat.shape
spatial_shape = (h, w)
feat = feat.flatten(3).permute(1, 0, 3, 2)
if self.use_cams_embeds:
feat = feat + self.cams_embeds[:, None, None, :].to(feat.dtype)
feat = feat + self.level_embeds[None, None, lvl:lvl + 1, :].to(feat.dtype)
spatial_shapes.append(spatial_shape)
feat_flatten.append(feat)
""" 对每个 camera 的所有层级特征进行汇聚 """
feat_flatten = torch.cat(feat_flatten, 2) # (cam, bs, sum(h*w), 256)
spatial_shapes = torch.as_tensor(spatial_shapes, dtype=torch.long, device=bev_pos.device)
# 计算每层特征的起始索引位置
level_start_index = torch.cat((spatial_shapes.new_zeros((1,)), spatial_shapes.prod(1).cumsum(0)[:-1]))
# 维度变换
feat_flatten = feat_flatten.permute(0, 2, 1, 3) # (num_cam, sum(H*W), bs, embed_dims)
输出bev_embedding:
"""
1. value: shape = (cam = 6, sum(h_i * w_i) = 30825, head = 8, dim = 32)
2. spatial_shapes = ([[116, 200], [58, 100], [29, 50], [15, 25]])
3. level_start_index= [0, 23200, 29000, 30450]
4. sampling_locations = (cam, max_len, 8, 4, 8, 2)
5. attention_weights = (cam, max_len, 8, 4, 8)
6. output = (cam, max_len, 8, 32)
"""
output = MultiScaleDeformableAttnFunction.apply(value, spatial_shapes, level_start_index, sampling_locations,
attention_weights, self.im2col_step)
"""最后再将六个环视相机查询到的特征整合到一起,再求一个平均值 """
for i, index_query_per_img in enumerate(indexes):
for j in range(bs): # slots: (bs, 40000, 256)
slots[j, index_query_per_img] += queries[j * self.num_cams + i, :len(index_query_per_img)]
count = bev_mask.sum(-1) > 0
count = count.permute(1, 2, 0).sum(-1)
count = torch.clamp(count, min=1.0)
slots = slots / count[..., None] # maybe normalize.
slots = self.output_proj(slots)
将 Temporal Self-Attetion 模块和 Spatial Cross-Attention 模块堆叠在一起,并重复六次,最终得到的 BEV Embedding 特征作为下游 3D 目标检测和道路分割任务的 BEV 空间特征。
具体代码详解:万字长文理解纯视觉感知算法 —— BEVFormer
Decoder模块
以上过程中,利用了当前帧之前所有帧的特征迭代修正,以获得prev_bev的特征,因此在使用 Decoder 模块进行解码之前,需要对当前时刻的 6 张环视图片同样使用 Backbone + Neck 提取多尺度特征,并使用上述 Temporal Self-Attention 模块和 Spatial Cross-Attention 模块的逻辑来生成当前时刻的bev_embedding特征。然后,将这部分特征输入到 Decoder 中进行 3D 目标检测。
分类分支的网络结构:
Sequential(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(2): ReLU(inplace=True)
(3): Linear(in_features=256, out_features=256, bias=True)
(4): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(5): ReLU(inplace=True)
(6): Linear(in_features=256, out_features=10, bias=True)
)
回归分支的网络结构:
Sequential(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): ReLU()
(2): Linear(in_features=256, out_features=256, bias=True)
(3): ReLU()
(4): Linear(in_features=256, out_features=10, bias=True)
)
算法创新
使用Transformer和时间结构来聚合时空信息
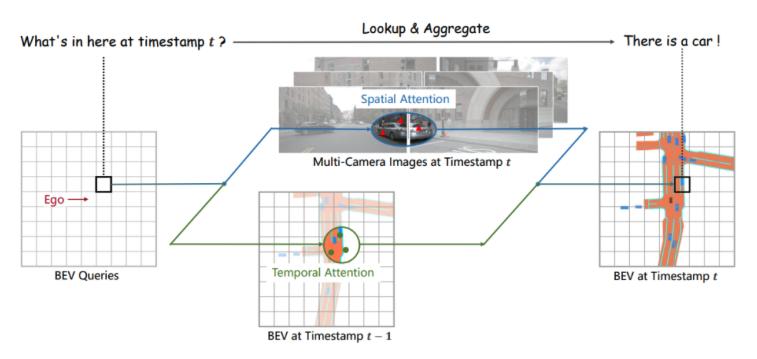
BEVFormer使用Transformer和时间结构来聚合来自多视角摄像机和历史BEV特征的时空信息。
具体来说,BEVFormer使用预定义的网格状BEV查询与空间/时间特征进行交互,以查找并聚合时空信息。这种方法可以有效地捕获3D场景中物体的时空关系,并生成更强大的表示。
使用查询来查找空间/时间空间并相应地聚合时空信息
除了使用Transformer和时间结构来聚合时空信息外,BEVFormer还使用查询来查找空间/时间空间并相应地聚合时空信息。
具体而言,BEVFormer使用两种类型的注意力机制:一种是用于跨摄像机视图之间的注意力机制(即“Spatial Cross-Attention”),另一种是用于历史BEV特征之间的注意力机制(即“Temporal Self-Attention”)。
这些注意力机制可以帮助BEVFormer有效地捕获3D场景中物体之间的关系,并生成更好的表征。
适用于多个3D感知任务
从BEVFormer生成的BEV特征可以同时支持多个3D感知任务,例如3D物体检测和地图分割。
这意味着,使用BEVFormer可以减少需要为不同任务训练不同模型的工作量,并提高系统整体性能。
SimpleBEV
核心点:BEV的基础框架
Fiety
核心点:训练和推断未来鸟瞰图
其余可参考内容记录: 计算机视觉算法——BEV Perception算法总结(3D LaneNet / LSS / PON / BEVFormer / GKT / Translating Image to Maps)