强化学习
...大约 3 分钟
深度度量学习
度量学习是从数据中学习一种度量数据对象间距离的方法。其目标是使得在学得的距离度量下,相似对象间的距离小,不相似对象间的距离大。
对于传统度量学习而言,由于其处理原始数据的能力有限,因此需要首先使用特征工程的知识对数据进行预处理,然后再用度量学习的算法进行学习。一些传统的度量学习方法只能学习出线性特征,虽然有一些能够提取非线性特征的核方法被提出,但对学习效果也没有明显提升。
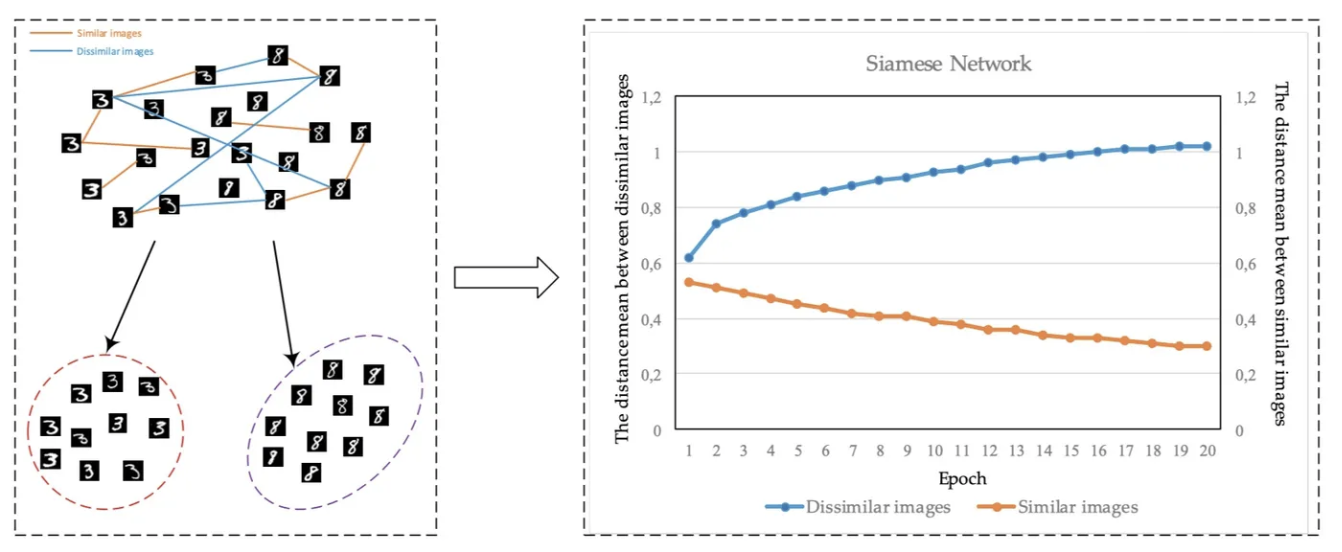
随着深度学习的出现,得益于激活函数学习非线性特征的优秀能力,深度学习方法能够自动地从原始数据中学出高质量的特征。因此深度学习的网络结构与传统的度量学习方法相结合能够带来理想的效果。如图2、所示,采用MNIST作为例子,左侧图中的橙色线条是同类样本之间的距离,蓝色线条是异类样本之间的距离。右侧图是随着训练的进行,这两种距离的变化趋势。可以看出同类样本间距离减小,异类样本间距离增加。
深度度量学习主要由三方面组成:样本挖掘、模型结构、损失函数;
样本挖掘
最容易能想到的样本挖掘方法是随机采集正负样本对。但是这种方法采集到的样本对不难区分,模型无法从这些数据中学到足够有信息量的知识。因此就需要采用一些样本挖掘方法,从数据集中找到难区分的样本对。
一组典型的样本由anchor、negative与positive组成。positive是和anchor类别相同的正样本,negative是和anchor类别不同副样本。根据anchor与正样本及负样本之间的距离不同,可以将样本挖掘分为如下3类。
- Hard Negative Mining:使用训练集训练后得到的假阳性样本作为负样本
- Semi-Hard Negative Mining:在某个margin范围内寻找负样本
- Easy Negative Mining:在某个margin范围外找到的负样本
进行样本挖掘的优点:
- 模型更容易学到有用的知识,有利于提升模型的区分能力。
- 有利于防止过拟合。如果模型一直看到容易区分的样本,容易使模型发生过拟合,陷入局部最优值。
- 有利于降低训练的时间复杂度。遍历数据中的所有(anchor, positive, negative)三元组需要O(n^3)的时间复杂度,而选择少量难以区分的数据对模型进行训练就可以达到同样的效果。
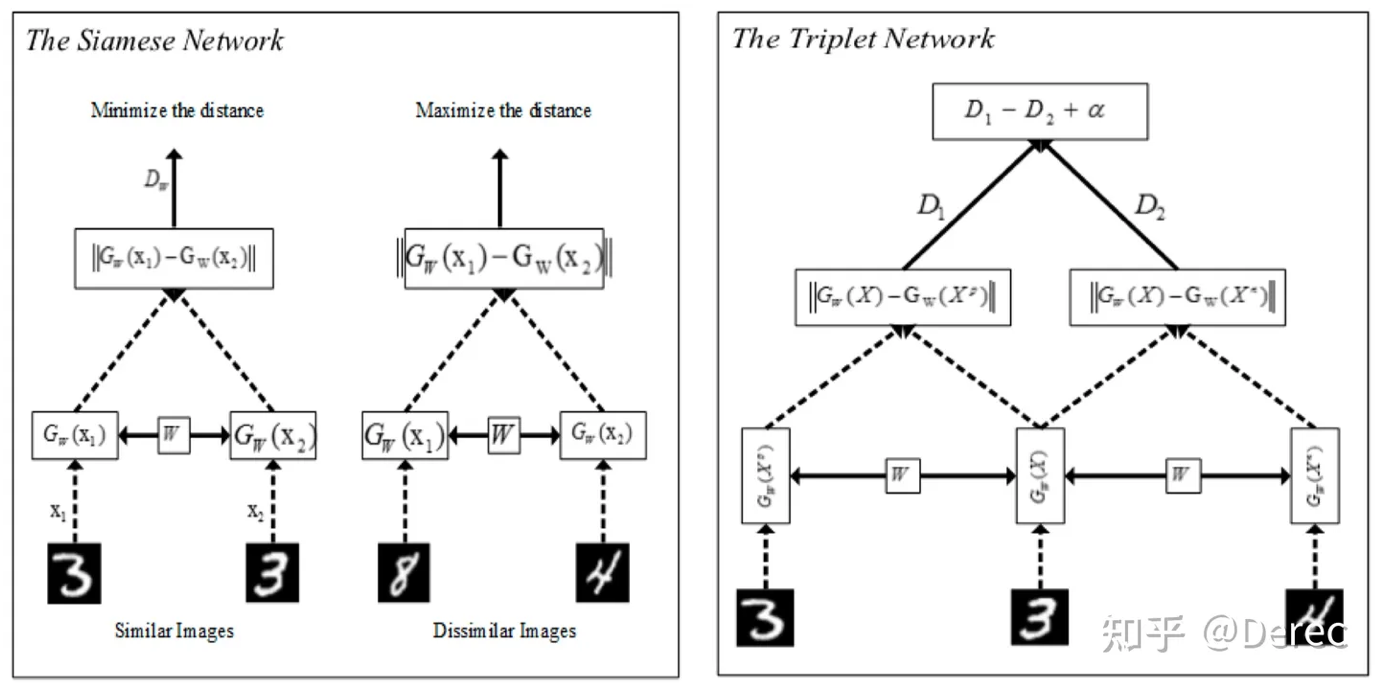
典型的对比学习模型结构
典型的对比学习模型结构有Siamese Network(孪生网络)和Triplet Network。模型架构图如图所示:
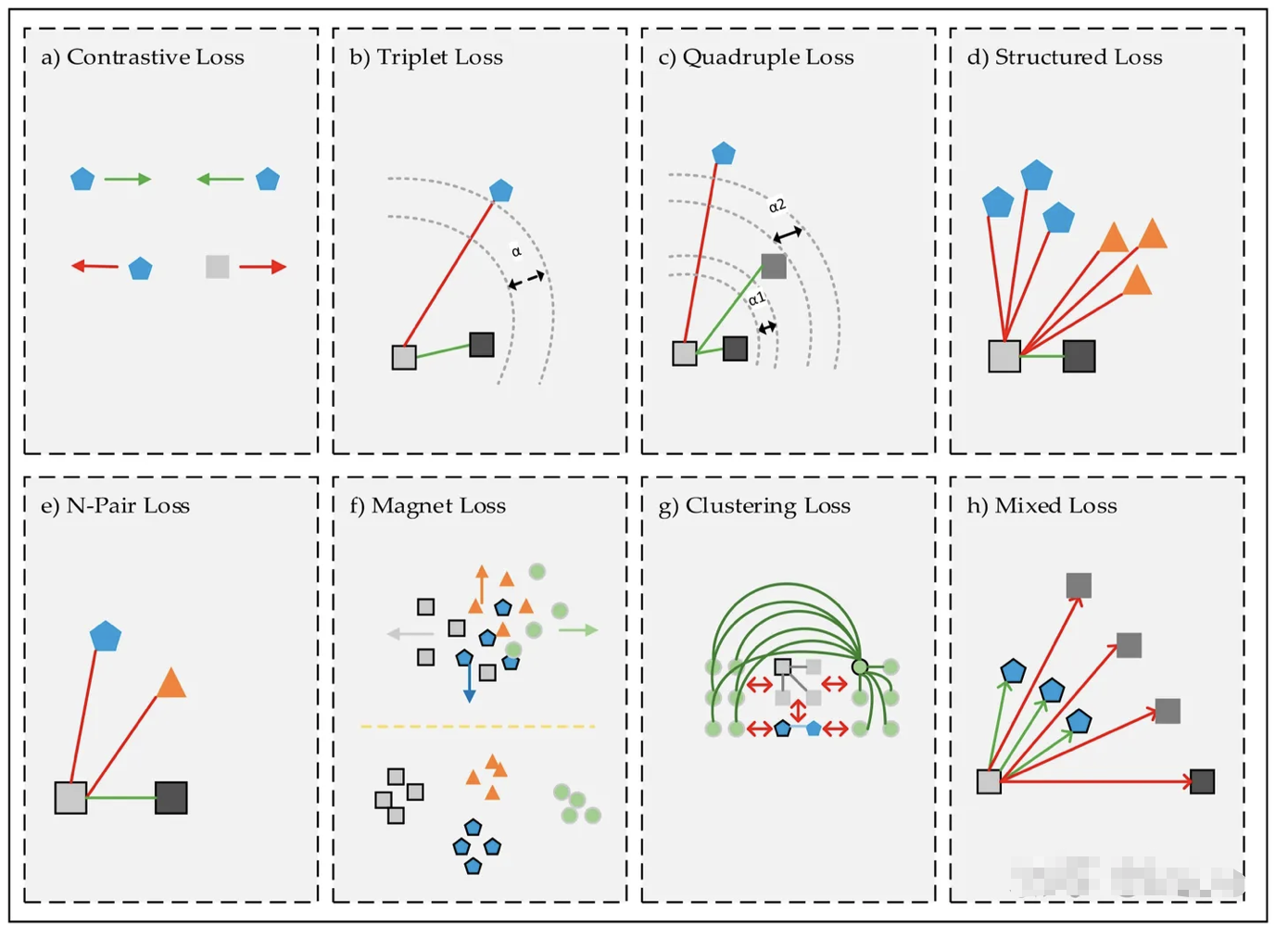
损失函数