
Llama
Llama1
之前人们发现,大模型和小模型相比,一开始小模型Loss下降的快,但随着训练继续进行,小模型趋于饱和,而大模型则可以获得更低的Loss,也就是说,比较大的训练预算下,大模型是比较划算的。
但是Meta不这么认为,Meta认为训练只会训练一次,而推理则会进行无数次,推理低价应该比训练代价更重要,相同的计算预算下,增加训练数据比扩大模型参数更有效,Llama1总共使用了1.4T token,训练时的上下文长度为2048,使用了2048个A100 80G GPU,总训练用时21天。
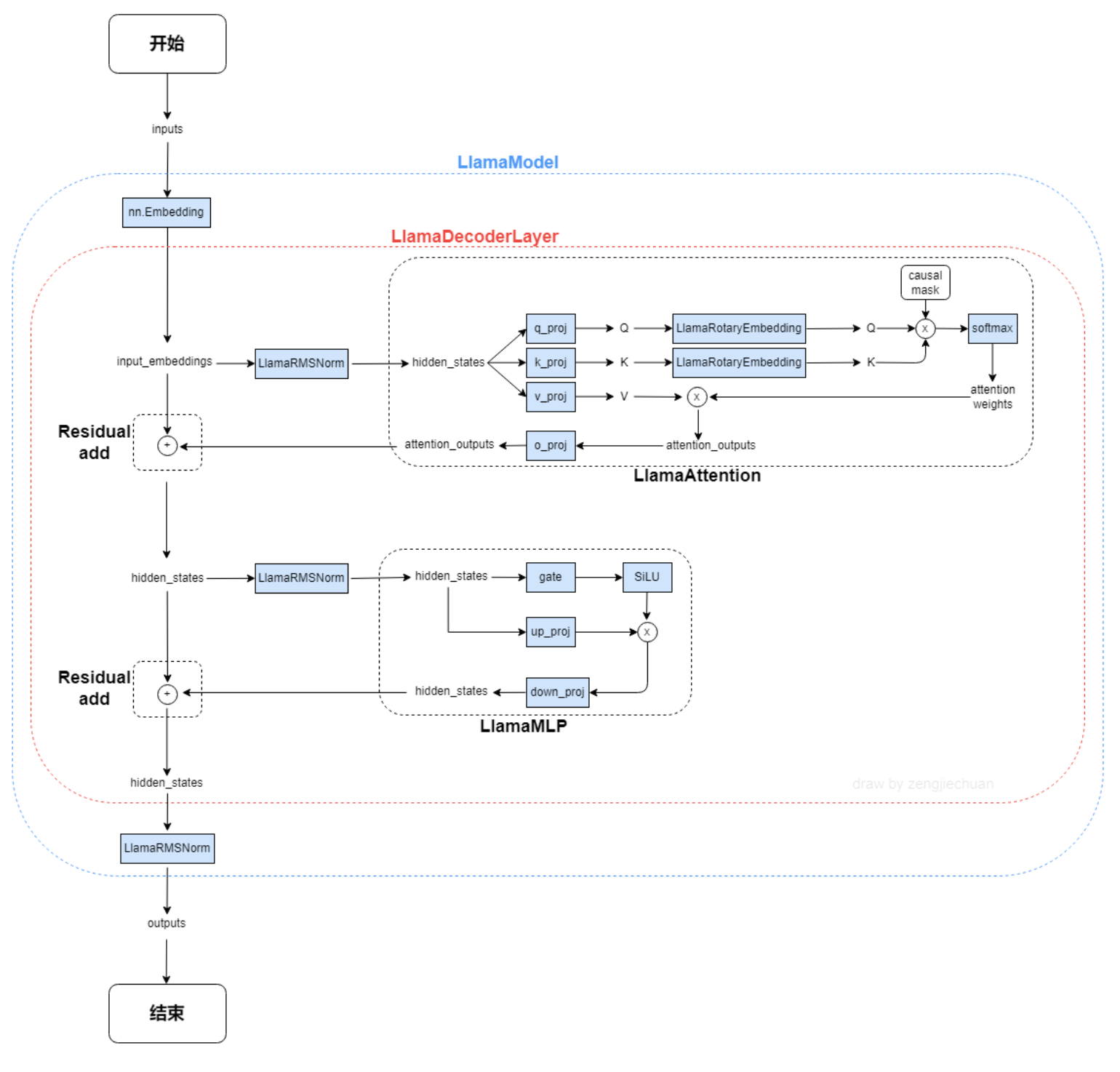
Llama1模型采用的是Transformer Decoder架构,做了以下修改:
- 和GPT3一样的将Norm从每个子层的输出位置移动到了输入位置。
- 将Layer Norm改为RMS Norm。
- 采用旋转位置编码。
- 采用silu激活函数。
RMS Norm
动机是其发现Layernorm在对特征进行norm时,对特征进行平移并不能改变特征的分布,所以其删去了所有平移操作。分母处的为防止除零进行的操作。
代码:
class LlamaRMSNorm(nn.Module):
def __init__(self, hidden_size, eps=1e-6):
super().__init__()
self.weight = nn.Parameter(torch.ones(hidden_size))
self.variance_epsilon = eps
def forward(self, hidden_states):
input_dtype = hidden_states.dtype
variance = hidden_states.to(torch.float32).pow(2).mean(-1, keepdim=True)
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
return (self.weight * hidden_states).to(input_dtype)
silu
silu是relu的一种变体,其在0处更为平滑,实验发现其可以提升精度,但和relu相比,因需要计算指数函数,计算代价较高。
RoPE
代码:
class LlamaRotaryEmbedding(torch.nn.Module):
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None):
super().__init__()
inv_freq = 1.0 / (base ** (torch.arange(0, dim, 2).float().to(device) / dim))
self.register_buffer("inv_freq", inv_freq)
# Build here to make `torch.jit.trace` work.
self.max_seq_len_cached = max_position_embeddings
t = torch.arange(self.max_seq_len_cached, device=self.inv_freq.device, dtype=self.inv_freq.dtype)
freqs = torch.einsum("i,j->ij", t, self.inv_freq)
# Different from paper, but it uses a different permutation in order to obtain the same calculation
emb = torch.cat((freqs, freqs), dim=-1)
self.register_buffer("cos_cached", emb.cos()[None, None, :, :], persistent=False)
self.register_buffer("sin_cached", emb.sin()[None, None, :, :], persistent=False)
def forward(self, x, seq_len=None):
# x: [bs, num_attention_heads, seq_len, head_size]
if seq_len > self.max_seq_len_cached:
self.max_seq_len_cached = seq_len
t = torch.arange(self.max_seq_len_cached, device=x.device, dtype=self.inv_freq.dtype)
freqs = torch.einsum("i,j->ij", t, self.inv_freq)
# Different from paper, but it uses a different permutation in order to obtain the same calculation
emb = torch.cat((freqs, freqs), dim=-1).to(x.device)
self.register_buffer("cos_cached", emb.cos()[None, None, :, :], persistent=False)
self.register_buffer("sin_cached", emb.sin()[None, None, :, :], persistent=False)
return (
self.cos_cached[:, :, :seq_len, ...].to(dtype=x.dtype),
self.sin_cached[:, :, :seq_len, ...].to(dtype=x.dtype),
)
Llama2
训练数据相比Llama1提升了40%,达到了2T个token,上下文长度也翻倍达到了4096,70B模型训练了172万GPU小时,相当于2048个A100训练35天。Llama2还通过了两个模型引入了安全奖励和有用奖励用作强化学习。
GQA
分组查询注意力 (Grouped Query Attention) 是一种在大型语言模型中的多查询注意力 (MQA) 和多头注意力 (MHA) 之间进行插值的方法,它的目标是在保持 MQA 速度的同时实现 MHA 的质量。GQA将查询头分成G组,每组共享一个键和值。可以表示为:
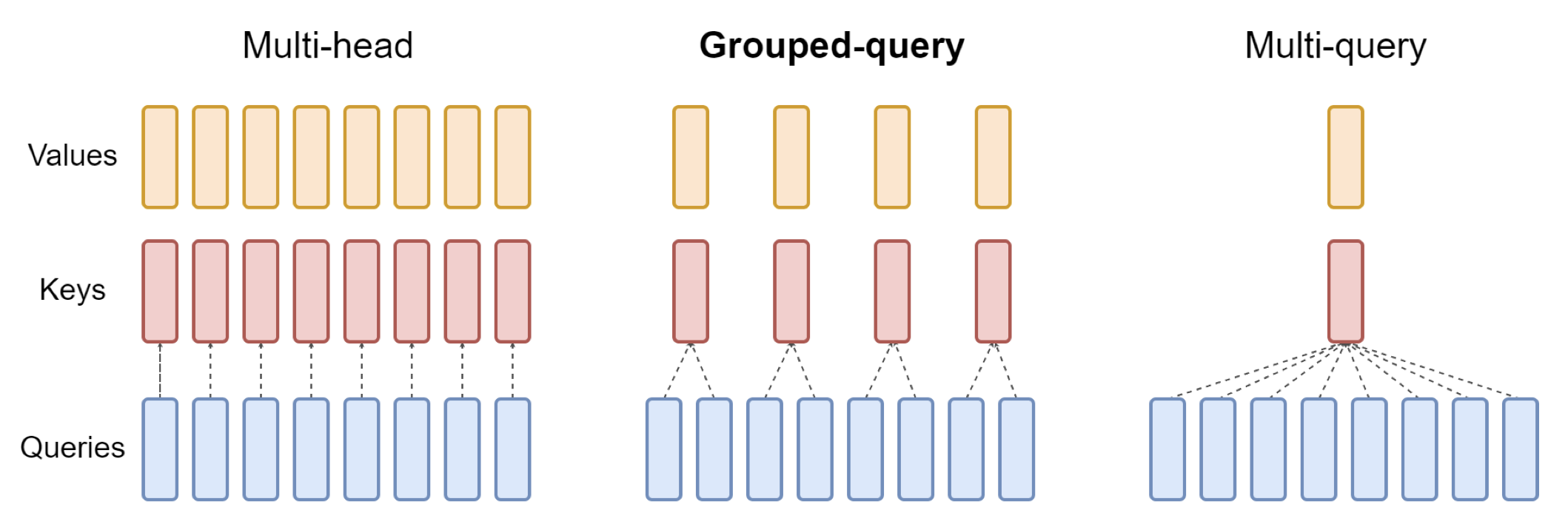
标准多头注意层(MHA)由H个查询头、键头和值头组成。每个头都有D个维度。Pytorch的代码如下:
from torch.nn.functional import scaled_dot_product_attention
# shapes: (batch_size, seq_len, num_heads, head_dim)
query = torch.randn(1, 256, 8, 64)
key = torch.randn(1, 256, 8, 64)
value = torch.randn(1, 256, 8, 64)
output = scaled_dot_product_attention(query, key, value)
print(output.shape) # torch.Size([1, 256, 8, 64])
代码实现
首先,定义查询、键和值。然后设置注意力头的数量,数量是随意的,但是要保证num_heads_for_query % num_heads_for_key = 0,也就是说要能够整除。我们的定义如下:
import torch
# shapes: (batch_size, seq_len, num_heads, head_dim)
query = torch.randn(1, 256, 8, 64)
key = torch.randn(1, 256, 2, 64)
value = torch.randn(1, 256, 2, 64)
num_head_groups = query.shape[2] // key.shape[2]
print(num_head_groups) # each group is of size 4 since there are 2 kv_heads
为了提高效率,交换seq_len和num_heads维度,einops可以像下面这样简单地完成:
from einops import rearrange
query = rearrange(query, "b n h d -> b h n d")
key = rearrange(key, "b s h d -> b h s d")
value = rearrange(value, "b s h d -> b h s d")
然后就是需要在查询矩阵中引入”分组“的概念。
from einops import rearrange
query = rearrange(query, "b (h g) n d -> b g h n d", g=num_head_groups)
print(query.shape) # torch.Size([1, 4, 2, 256, 64])
上面的代码我们将二维重塑为二维:对于我们定义的张量,原始维度8(查询的头数)现在被分成两组(以匹配键和值中的头数),每组大小为4。
最后最难的部分是计算注意力的分数。但其实它可以在一行中通过insum操作完成的
from einops import einsum, rearrange
# g stands for the number of groups
# h stands for the hidden dim
# n and s are equal and stands for sequence length
scores = einsum(query, key, "b g h n d, b h s d -> b h n s")
print(scores.shape) # torch.Size([1, 2, 256, 256])
scores张量和上面的value张量的形状是一样的。我们看看到底是怎么操作的:
einsum帮我们做了两件事:
- 一个查询和键的矩阵乘法。在我们的例子中,这些张量的形状是(1,4,2,256,64)和(1,2,256,64),所以沿着最后两个维度的矩阵乘法得到(1,4,2,256,256)。
- 对第二个维度(维度g)上的元素求和——如果在指定的输出形状中省略了维度,einsum将自动完成这项工作,这样的求和是用来匹配键和值中的头的数量。
最后是注意分数与值的标准乘法:
import torch.nn.functional as F
scale = query.size(-1) ** 0.5
attention = F.softmax(similarity / scale, dim=-1)
# here we do just a standard matrix multiplication
out = einsum(attention, value, "b h n s, b h s d -> b h n d")
# finally, just reshape back to the (batch_size, seq_len, num_kv_heads, hidden_dim)
out = rearrange(out, "b h n d -> b n h d")
print(out.shape) # torch.Size([1, 256, 2, 64])
这样最简单的GQA实现就完成了。
kv cache
本部分较多参考自知乎:大模型推理性能优化之KV Cache解读
问题
大模型推理性能优化的一个常用技术是KV Cache,该技术可以在不影响任何计算精度的前提下,通过空间换时间思想,提高推理性能。
- KV Cache节省了Self-Attention层中哪部分的计算?
- KV Cache对MLP层的计算量有影响吗?
- KV Cache对block间的数据传输量有影响吗?
NLP推理过程
生成式generative模型的推理过程很有特点,我们给一个输入文本,模型会输出一个回答(长度为N),其实该过程中执行了N次推理过程。即GPT类模型一次推理只输出一个token,输出token会与输入tokens 拼接在一起,然后作为下一次推理的输入,这样不断反复直到遇到终止符。
如上描述是我们通常认知的GPT推理过程。代码描述如下:
import torch
from transformers import GPT2LMHeadModel, GPT2Tokenizer
model = GPT2LMHeadModel.from_pretrained("/WORK/Test/gpt", torchscript=True).eval()
# tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("/WORK/Test/gpt")
in_text = "Lionel Messi is a"
in_tokens = torch.tensor(tokenizer.encode(in_text))
# inference
token_eos = torch.tensor([198]) # line break symbol
out_token = None
i = 0
with torch.no_grad():
while out_token != token_eos:
logits, _ = model(in_tokens)
out_token = torch.argmax(logits[-1, :], dim=0, keepdim=True)
in_tokens = torch.cat((in_tokens, out_token), 0)
text = tokenizer.decode(in_tokens)
print(f'step {i} input: {text}', flush=True)
i += 1
out_text = tokenizer.decode(in_tokens)
print(f' Input: {in_text}')
print(f'Output: {out_text}')
输出:
step 0 input: Lionel Messi is a player
step 1 input: Lionel Messi is a player who
step 2 input: Lionel Messi is a player who has
step 3 input: Lionel Messi is a player who has been
step 4 input: Lionel Messi is a player who has been a
step 5 input: Lionel Messi is a player who has been a key
step 6 input: Lionel Messi is a player who has been a key part
step 7 input: Lionel Messi is a player who has been a key part of
step 8 input: Lionel Messi is a player who has been a key part of the
step 9 input: Lionel Messi is a player who has been a key part of the team
step 10 input: Lionel Messi is a player who has been a key part of the team's
step 11 input: Lionel Messi is a player who has been a key part of the team's success
step 12 input: Lionel Messi is a player who has been a key part of the team's success.
Input: Lionel Messi is a
Output: Lionel Messi is a player who has been a key part of the team's success.
可以看出如上计算的问题吗?每次推理过程的输入tokens都变长了,导致推理FLOPs随之增大。有方法实现推理过程的FLOPs基本恒定不变或变小吗?(埋个伏笔,注意是基本恒定)。
原理
在上面的推理过程中,每 step 内,输入一个 token序列,经过Embedding层将输入token序列变为一个三维张量[b, s, h],经过一通计算,最后经logits层将计算结果映射至词表空间,输出张量维度为[b, s, vocab_size]。
当前轮输出token与输入tokens拼接,并作为下一轮的输入tokens,反复多次。可以看出第轮输入数据只比第轮输入数据新增了一个token,其他全部相同!因此第轮推理时必然包含了第轮的部分计算。KV Cache的出发点就在这里,缓存当前轮可重复利用的计算结果,下一轮计算时直接读取缓存结果,就是这么简单,不存在什么Cache miss问题。
实现细节
目前各大模型推理都实现了KV Cache,下面就看如何使用了。我们可以在上面代码基础上修改,主要改动:
在推理时新增了 past_key_values 参数,该参数就会以追加方式保存每一轮的K V值。kvcache变量内容为((k,v), (k,v), ..., (k,v)),即有个 k,v 组成的一个元组,其中 k 和 v 的维度均为 [b, n_head, s, head_dims]。这里可以顺带计算出每轮推理对应的 cache 数据量为,这里值等于当前轮次值。以GPT3-175B为例,假设以 float16 来保存 KV cache,senquence长度为100,batchsize=1,则 KV cache占用显存为 2×100×12288×96×2 Byte= 472MB。
推理输出的token直接作为下一轮的输入,不再拼接,因为上文信息已经在 kvcache 中。
代码示例:
import torch
from transformers import GPT2LMHeadModel, GPT2Tokenizer
model = GPT2LMHeadModel.from_pretrained("/WORK/Test/gpt", torchscript=True).eval()
# tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("/WORK/Test/gpt")
in_text = "Lionel Messi is a"
in_tokens = torch.tensor(tokenizer.encode(in_text))
# inference
token_eos = torch.tensor([198]) # line break symbol
out_token = None
kvcache = None
out_text = in_text
i = 0
with torch.no_grad():
while out_token != token_eos:
logits, kvcache = model(in_tokens, past_key_values=kvcache) # 增加了一个 past_key_values 的参数
out_token = torch.argmax(logits[-1, :], dim=0, keepdim=True)
in_tokens = out_token # 输出 token 直接作为下一轮的输入,不再拼接
text = tokenizer.decode(in_tokens)
print(f'step {i} input: {text}', flush=True)
i += 1
out_text += text
print(f' Input: {in_text}')
print(f'Output: {out_text}')
通过上面代码只能看到调用层面的变化,实现细节还需看各框架的底层实现,例如Hugging Face的transformers库代码实现就比较清爽,在modeling_gpt2.py中Attention部分相关代码如下:
query = self._split_heads(query, self.num_heads, self.head_dim)
key = self._split_heads(key, self.num_heads, self.head_dim)
value = self._split_heads(value, self.num_heads, self.head_dim)
if layer_past is not None: # 当输出第一个token后,layer_past就是非None了
past_key, past_value = layer_past # 取出之前计算好的 key, value
key = torch.cat((past_key, key), dim=-2) # past_key 与当前 token 对应的 key 拼接
value = torch.cat((past_value, value), dim=-2) # past_value 与当前 token 对应的 value 拼接
if use_cache is True:
present = (key, value)
else:
present = None
在block层面也有相关代码,大家有空细品吧。还是那句话,说一千道一万不如阅读并运行源码一次。
其实,KV Cache配置开启后,推理过程可以分为2个阶段:
预填充阶段:发生在计算第一个输出token过程中,这时Cache是空的,计算时需要为每个 transformer layer 计算并保存key cache和value cache,在输出token时Cache完成填充;FLOPs同KV Cache关闭一致,存在大量gemm操作,推理速度慢。
使用KV Cache阶段:发生在计算第二个输出token至最后一个token过程中,这时Cache是有值的,每轮推理只需读取Cache,同时将当前轮计算出的新的Key、Value追加写入至Cache;FLOPs降低,gemm变为gemv操作,推理速度相对第一阶段变快,这时属于Memory-bound类型计算。
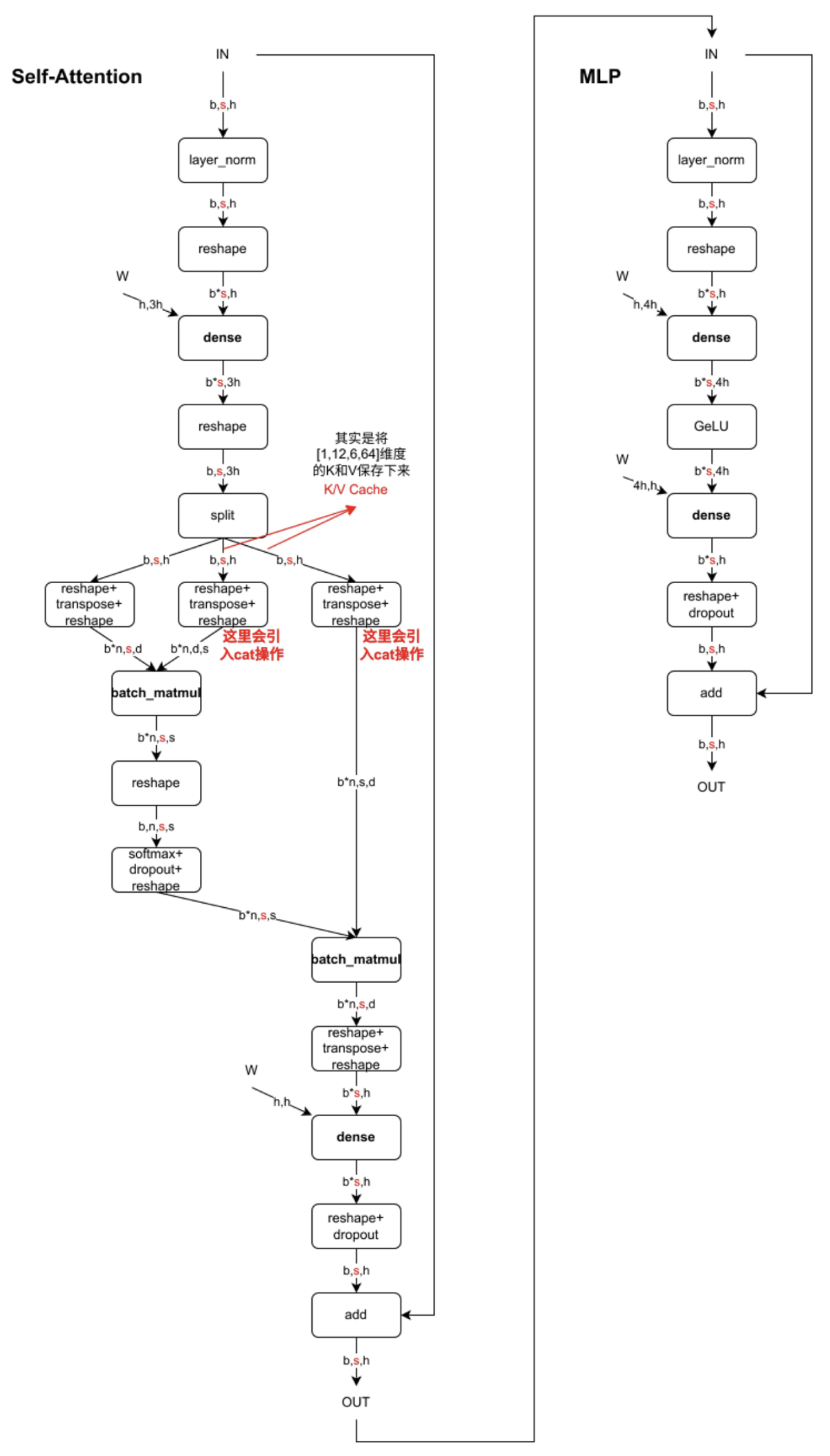
这里用图可能更有助理解,下图是一个Decoder Block(仅以MHA为例),含有Self-Attention和MLP,标红部分为KV Cache影响到的内容,即KV Cache开启后,标红的序列长度 变为 1,当batch_size=1时,Self-Attention中的2个dense全都变为gemv操作,MLP中的dense也全都变为gemv操作。看懂这个图就可以答对上面的3个问题啦。图中数据维度相关字母的含义:
- b: batchsize
- s: sequence length,序列长度
- h: hidden_state 维度 = n * d
- n: head 个数
- d: head 维度
如下链接也有这方面的定量分析,写的很棒,推荐大家看看。
总结
KV Cache是Transformer推理性能优化的一项重要工程化技术,各大推理框架都已实现并将其进行了封装(例如 transformers库 generate 函数已经将其封装,用户不需要手动传入past_key_values)并默认开启(config.json文件中use_cache=True)。