Llama1
之前人们发现,大模型和小模型相比,一开始小模型Loss下降的快,但随着训练继续进行,小模型趋于饱和,而大模型则可以获得更低的Loss,也就是说,比较大的训练预算下,大模型是比较划算的。
但是Meta不这么认为,Meta认为训练只会训练一次,而推理则会进行无数次,推理低价应该比训练代价更重要,相同的计算预算下,增加训练数据比扩大模型参数更有效,Llama1总共使用了1.4T token,训练时的上下文长度为2048,使用了2048个A100 80G GPU,总训练用时21天。
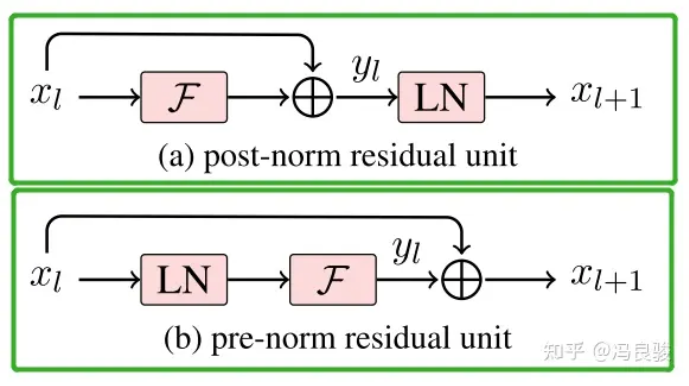
Llama1模型采用的是Transformer Decoder架构,做了以下修改:
...大约 11 分钟