
标准化总结
昇腾大模型|结构组件-1——Layer Norm、RMS Norm、Deep Norm
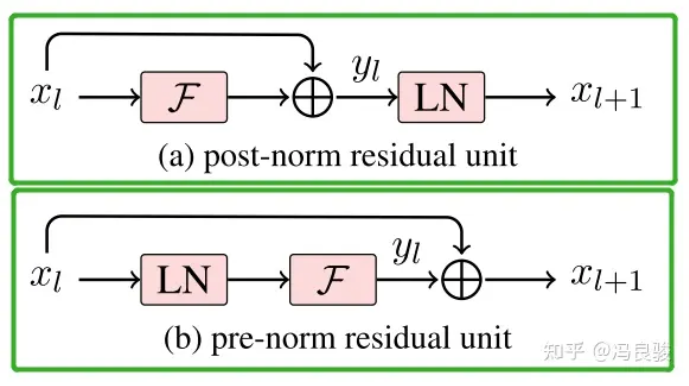
一般认为,Post-Norm在残差之后做归一化,对参数正则化的效果更强,进而模型的收敛性也会更好;而Pre-Norm有一部分参数直接加在了后面,没有对这部分参数进行正则化,可以在反向时防止梯度爆炸或者梯度消失,大模型的训练难度大,因而使用Pre-Norm较多。
BatchNorm
提示
论文题目:Batch Normalization: Accelerating Deep Network Training byReducing Internal Covariate Shift
论文地址:https://arxiv.org/pdf/1502.03167.pdf
公式及参数
参数:
- (可学习参数)γ : weight of BatchNorm
- (可学习参数)β : bias of BatchNorm
- (统计量)running mean: 预测阶段会使用这个均值
- (统计量)running var: 预测阶段会使用这个方差
优缺点
BN的优点:
- 解决内部协变量偏移,简单来说训练过程中,各层分布不同,增大了学习难度,BN缓解了这个问题。当然后来也有论文证明BN有作用和这个没关系,而是可以使损失平面更加的平滑,从而加快收敛速度。
- 缓解了梯度饱和问题(如果使用sigmoid这种含有饱和区间的激活函数的话),加快收敛。
BN的缺点:
- Batch size比较小的时候,效果会比较差。因为他是用一个batch中的均值和方差来模拟全部数据的均值和方差。比如你一个batch只有2个样本,那你两个样本的均值和方差就不能很好地代表全班人的均值和方差,所以效果肯定就不好。
- BN是计算机视觉CV的标配,但在自然语音处理NLP中效果一般较差,取而代之的是LN。
其他信息
Q:BatchNorm2d的参数γ和β数量是跟特征图的数量是一致的,并不是我们直观认为的num_featureHW个参数,这是为什么呢?
A:《百面机器学习》P221是这样解释的: BatchNorm批量归一化在卷积神经网络中应用时,需要注意卷积神经网络的参数共享机制。每一个卷积核的参数在不同位置的神经元当中是共享的,因此同一个特征图的所有神经元也应该被一起归一化!
换句话说就是,你一个特征图用的是共享的卷积核参数,所以这个特征图中的每个神经元(共H*W个)也应该共享参数, 。如果有个卷积核,就对应个特征图和组不同的 和参数。
另一个解释:
假如某一层卷积层有6个特征图,每个特征图的大小是100*100,这样就相当于这一层网络有6*100*100个神经元,如果采用BN,就会有6*100*100个参数γ、β,这样岂不是太恐怖了。因此卷积层上的BN使用,其实也是使用了类似权值共享的策略,把一整张特征图当做一个神经元进行处理。
卷积神经网络经过卷积后得到的是一系列的特征图,如果min-batch sizes为m,那么网络某一层输入数据可以表示为四维矩阵(m,f,p,q),m为min-batch sizes,f为特征图个数,p、q分别为特征图的宽高。在cnn中我们可以把每个特征图看成是一个特征处理,因此在使用Batch Normalization,mini-batch size 的大小相当于m*p*q,于是对于每个特征图都只有一对可学习参数:γ、β。
总结来说:
对于某个特征图而言,一个batch共有m个这样的特征图,并且每个特征图有pq个神经元,把所有的m*p*q个神经元拉直,然后求得平均值和方差。 对m个这样特征图的pq个神经元的每个神经元,利用求出的平均值和方差做下数据变换。
LayerNorm
LayerNorm是大模型也是transformer结构中最常用的归一化操作,简而言之,它的作用是对特征张量按照某一维度或某几个维度进行0均值,1方差的归一化操作。

nn.LayerNorm(normalized_shape, eps=1e-05, elementwise_affine=True, device=None, dtype=None)
- normalized_shape:归一化的维度,int(最后一维)list(list里面的维度),还是以(2,2,4)为例,如果输入是int,则必须是4,如果是list,则可以是[4], [2,4], [2,2,4],即最后一维,倒数两维,和所有维度。
- eps:加在分母方差上的偏置项,防止分母为0。
- elementwise_affine:是否使用可学习的参数和,前者开始为1,后者为0,设置该变量为True,则二者均可学习随着训练过程而变化。
BatchNorm 与 LayerNorm
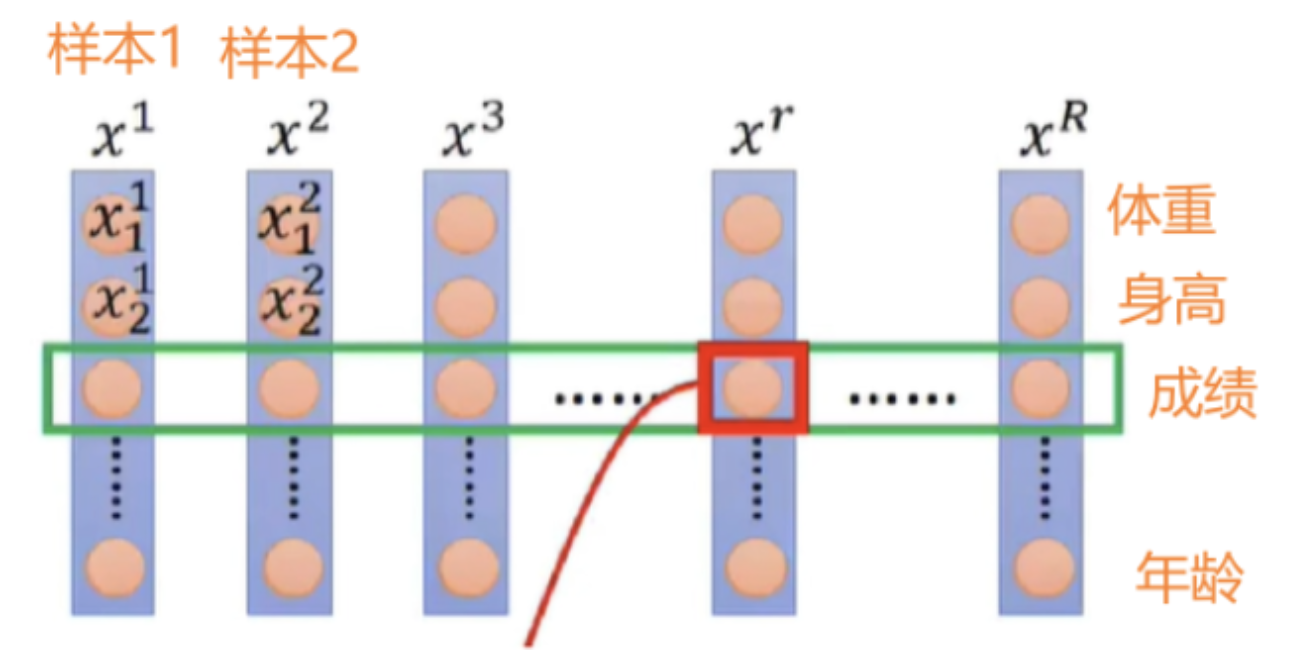
BN抹平了不同特征之间的大小关系,而保留了不同样本之间的大小关系。这样,如果具体任务依赖于不同样本之间的关系,BN更有效,尤其是在CV领域,例如不同图片样本进行分类,不同样本之间的大小关系得以保留。
LN抹平了不同样本之间的大小关系,而保留了不同特征之间的大小关系。所以,LN更适合NLP领域的任务,其中,一个样本的特征实际上就是不同word embedding,通过LN可以保留特征之间的这种时序关系。
Layer Normalization和Batch Normalization一样都是一种归一化方法,因此,BatchNorm的好处LN也有,当然也有自己的好处:比如稳定后向的梯度,且作用大于稳定输入分布。然而BN无法胜任mini-batch size很小的情况,也很难应用于RNN。LN特别适合处理变长数据,因为是对channel维度做操作(这里指NLP中的hidden维度),和句子长度和batch大小无关。BN比LN在inference的时候快,因为不需要计算mean和variance,直接用running mean和running variance就行。
BN和LN在实现上的区别仅仅是:BN是对batch的维度去做归一化,也就是针对不同样本的同一特征做操作。LN是对hidden的维度去做归一化,也就是针对单个样本的不同特征做操作。因此,他们都可以归结为:减去均值除以标准差,施以线性映射。
对于NLP data来说,Transformer中应用BN并不好用,原因是前向和反向传播中,batch统计量及其梯度都不太稳定。而对于VIT来说,BN也不是不能用,但是需要在FFN里面的两层之间插一个BN层来normalized。
RMSNorm
动机是其发现Layernorm在对特征进行norm时,对特征进行平移并不能改变特征的分布,所以其删去了所有平移操作。作者认为这种模式在简化了Layer Norm的同时,可以在各个模型上减少约 7%∼64% 的计算时间。另外,分母处的为防止除零进行的操作。
class RMSNorm(torch.nn.Module):
def __init__(self, dim: int, eps: float = 1e-6):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(dim))
def _norm(self, x):
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps) ###RMS Norm公式
def forward(self, x):
if rms_norm is not None and x.is_cuda:
return rms_norm(x, self.weight, self.eps)
else:
output = self._norm(x.float()).type_as(x)
return output * self.weight
Deep Norm
【DL&NLP】再谈Layer-Norm:Pre-LN、Post-LN、DeepNorm
优质参考资料
【深度学习基础】BatchNorm,LayerNorm,InstanceNorm,GroupNorm 和 WeightNorm 的原理与PyTorch逐行实现