
Python codebook
数据结构和算法
global 和 nonlocal
第一,两者的功能不同。global关键字修饰变量后标识该变量是全局变量,对该变量进行修改就是修改全局变量,而nonlocal关键字修饰变量后标识该变量是上一级函数中的局部变量,如果上一级函数中不存在该局部变量,nonlocal位置会发生错误(最上层的函数使用nonlocal修饰变量必定会报错)。
第二,两者使用的范围不同。global关键字可以用在任何地方,包括最上层函数中和嵌套函数中,即使之前未定义该变量,global修饰后也可以直接使用,而nonlocal关键字只能用于嵌套函数中,并且外层函数中定义了相应的局部变量,否则会发生错误(见第一)。
global关键字
global关键字用来在函数或其他局部作用域中使用全局变量。但是如果不修改全局变量也可以不使用global关键字。
gcount = 0 def global_test(): gcount+=1 print (gcount) global_test() UnboundLocalError: local variable 'gcount' referenced before assignment以上代码会报错:第一行定义了全局变量,在内部函数中又对外部函数进行了引用并修改,那么python会认为它是一个局部变量,有因为内部函数没有对其gcount进行定义和赋值,所以报错。
如果局部要对全局变量修改,则在局部声明该全局变量。
gcount = 0 def global_test(): global gcount gcount+=1 print (gcount) global_test() >>> 1如果局部不声明全局变量,并且不修改全局变量,则可以正常使用。
gcount = 0 def global_test(): print (gcount) global_test() >>> 0
nonlocal关键字
nonlocal声明的变量不是局部变量,也不是全局变量,而是外部嵌套函数内的变量。
def make_counter(): count = 0 def counter(): nonlocal count count += 1 return count return counter def make_counter_test(): mc = make_counter() print(mc()) print(mc()) make_counter_test() 1 2global和nonlocal混合使用
def scope_test():
def do_local():
spam = "local spam" #此函数定义了另外的一个spam字符串变量,并且生命周期只在此函数内。此处的spam和外层的spam是两个变量,如果写出spam = spam + “local spam” 会报错
def do_nonlocal():
nonlocal spam #使用外层的spam变量
spam = "nonlocal spam"
def do_global():
global spam
spam = "global spam"
spam = "test spam"
do_local()
print("After local assignmane:", spam)
do_nonlocal()
print("After nonlocal assignment:",spam)
do_global()
print("After global assignment:",spam)
scope_test()
print("In global scope:",spam)
After local assignment: test spam
After nonlocal assignment: nonlocal spam
After global assignment: nonlocal spam
In global scope: global spam
将序列分解为单独的变量
只要对象是可迭代的,就可以执行分解操作。 包括字符串,文件对象,迭代器和生成器。
data = [ 'ACME', 50, 91.1, (2012, 12, 21) ]
_, shares, price, _ = data
_为占位符,以用于只解压一部分值丢掉其他值。
解压可迭代对象赋值给多个变量
record = ('Dave', 'dave@example.com', '773-555-1212', '847-555-1212')
name, email, *phone_numbers = record
# phone_numbers:['773-555-1212', '847-555-1212']
值得注意的是上面解压出的 phone_numbers 变量永远都是列表类型,不管解压的电话号码数量是多少(包括 0 个)。 所以,任何使用到 phone_numbers 变量的代码就不需要做多余的类型检查去确认它是否是列表类型了。
星号表达式在迭代元素为可变长元组的序列时是很有用的。 比如,下面是一个带有标签的元组序列:
records = [
('foo', 1, 2),
('bar', 'hello'),
('foo', 3, 4),
]
def do_foo(x, y):
print('foo', x, y)
def do_bar(s):
print('bar', s)
for tag, *args in records:
if tag == 'foo':
do_foo(*args)
elif tag == 'bar':
do_bar(*args)
有时候,你想解压一些元素后丢弃它们,你不能简单就使用 * , 但是你可以使用一个普通的废弃名称,比如 _ 或者 ign (ignore)。
record = ('ACME', 50, 123.45, (12, 18, 2012))
name, *_, (*_, year) = record
在很多函数式语言中,星号解压语法跟列表处理有许多相似之处。比如,如果你有一个列表, 你可以很容易的将它分割成前后两部分:
>>> items = [1, 10, 7, 4, 5, 9]
>>> head, *tail = items
如果你够聪明的话,还能用这种分割语法去巧妙的实现递归算法。比如:
>>> def sum(items):
... head, *tail = items
... return head + sum(tail) if tail else head
...
>>> sum(items)
36
然后,由于语言层面的限制,递归并不是 Python 擅长的。 因此,最后那个递归演示仅仅是个好奇的探索罢了,对这个不要太认真了。
保留最后 N 个元素
保留有限历史记录正是 collections.deque 大显身手的时候。比如,下面的代码在多行上面做简单的文本匹配, 并返回匹配所在行的最后N行:
from collections import deque
def search(lines, pattern, history=5):
previous_lines = deque(maxlen=history)
for line in lines:
if pattern in line:
yield line, previous_lines
previous_lines.append(line)
# Example use on a file
if __name__ == '__main__':
with open(r'../../cookbook/somefile.txt') as f:
for line, prevlines in search(f, 'python', 5):
for pline in prevlines:
print(pline, end='')
print(line, end='')
print('-' * 20)
队列数据结构
更一般的, deque 类可以被用在任何你只需要一个简单队列数据结构的场合。 如果你不设置最大队列大小,那么就会得到一个无限大小队列,你可以在队列的两端执行添加和弹出元素的操作。
代码示例:
>>> q = deque()
>>> q.append(1)
>>> q.append(2)
>>> q.append(3)
>>> q
deque([1, 2, 3])
>>> q.appendleft(4)
>>> q
deque([4, 1, 2, 3])
>>> q.pop()
3
>>> q
deque([4, 1, 2])
>>> q.popleft()
4
在队列两端插入或删除元素时间复杂度都是O(1) ,区别于列表,在列表的开头插入或删除元素的时间复杂度为O(N) 。
查找最大或最小的 N 个元素
heapq 模块有两个函数:nlargest() 和 nsmallest() 可以完美解决这个问题。
import heapq
nums = [1, 8, 2, 23, 7, -4, 18, 23, 42, 37, 2]
print(heapq.nlargest(3, nums)) # Prints [42, 37, 23]
print(heapq.nsmallest(3, nums)) # Prints [-4, 1, 2]
两个函数都能接受一个关键字参数,用于更复杂的数据结构中:
portfolio = [
{'name': 'IBM', 'shares': 100, 'price': 91.1},
{'name': 'AAPL', 'shares': 50, 'price': 543.22},
{'name': 'FB', 'shares': 200, 'price': 21.09},
{'name': 'HPQ', 'shares': 35, 'price': 31.75},
{'name': 'YHOO', 'shares': 45, 'price': 16.35},
{'name': 'ACME', 'shares': 75, 'price': 115.65}
]
cheap = heapq.nsmallest(3, portfolio, key=lambda s: s['price'])
expensive = heapq.nlargest(3, portfolio, key=lambda s: s['price'])
如果你想在一个集合中查找最小或最大的 N 个元素,并且 N 小于集合元素数量,那么这些函数提供了很好的性能。 因为在底层实现里面,首先会先将集合数据进行堆排序后放入一个列表中:
>>> nums = [1, 8, 2, 23, 7, -4, 18, 23, 42, 37, 2]
>>> import heapq
>>> heap = list(nums)
>>> heapq.heapify(heap)
>>> heap
[-4, 2, 1, 23, 7, 2, 18, 23, 42, 37, 8]
堆数据结构最重要的特征是 heap[0] 永远是最小的元素。并且剩余的元素可以很容易的通过调用 heapq.heappop() 方法得到, 该方法会先将第一个元素弹出来,然后用下一个最小的元素来取代被弹出元素(这种操作时间复杂度仅仅是 O(log N),N 是堆大小)。 比如,如果想要查找最小的 3 个元素,你可以这样做:
>>> heapq.heappop(heap)
-4
>>> heapq.heappop(heap)
1
>>> heapq.heappop(heap)
2
当要查找的元素个数相对比较小的时候,函数 nlargest() 和 nsmallest() 是很合适的。 如果你仅仅想查找唯一的最小或最大(N=1)的元素的话,那么使用 min() 和 max() 函数会更快些。 类似的,如果 N 的大小和集合大小接近的时候,通常先排序这个集合然后再使用切片操作会更快点 ( sorted(items)[:N] 或者是 sorted(items)[-N:] )。 需要在正确场合使用函数 nlargest() 和 nsmallest() 才能发挥它们的优势 (如果 N 快接近集合大小了,那么使用排序操作会更好些)。
序列中出现次数最多的元素
collections.Counter 类就是专门为这类问题而设计的, 它甚至有一个有用的 most_common() 方法直接给了你答案。
为了演示,先假设你有一个单词列表并且想找出哪个单词出现频率最高。你可以这样做:
words = [
'look', 'into', 'my', 'eyes', 'look', 'into', 'my', 'eyes',
'the', 'eyes', 'the', 'eyes', 'the', 'eyes', 'not', 'around', 'the',
'eyes', "don't", 'look', 'around', 'the', 'eyes', 'look', 'into',
'my', 'eyes', "you're", 'under'
]
from collections import Counter
word_counts = Counter(words)
# 出现频率最高的3个单词
top_three = word_counts.most_common(3)
print(top_three)
# Outputs [('eyes', 8), ('the', 5), ('look', 4)]
Counter 实例一个鲜为人知的特性是它们可以很容易的跟数学运算操作相结合。比如:
>>> a = Counter(words)
>>> b = Counter(morewords)
>>> a
Counter({'eyes': 8, 'the': 5, 'look': 4, 'into': 3, 'my': 3, 'around': 2,
"you're": 1, "don't": 1, 'under': 1, 'not': 1})
>>> b
Counter({'eyes': 1, 'looking': 1, 'are': 1, 'in': 1, 'not': 1, 'you': 1,
'my': 1, 'why': 1})
>>> # Combine counts
>>> c = a + b
>>> c
Counter({'eyes': 9, 'the': 5, 'look': 4, 'my': 4, 'into': 3, 'not': 2,
'around': 2, "you're": 1, "don't": 1, 'in': 1, 'why': 1,
'looking': 1, 'are': 1, 'under': 1, 'you': 1})
>>> # Subtract counts
>>> d = a - b
>>> d
Counter({'eyes': 7, 'the': 5, 'look': 4, 'into': 3, 'my': 2, 'around': 2,
"you're": 1, "don't": 1, 'under': 1})
过滤序列元素
最简单的过滤序列元素的方法就是使用列表推导。比如:
>>> mylist = [1, 4, -5, 10, -7, 2, 3, -1]
>>> [n for n in mylist if n > 0]
[1, 4, 10, 2, 3]
>>> [n for n in mylist if n < 0]
[-5, -7, -1]
使用列表推导的一个潜在缺陷就是如果输入非常大的时候会产生一个非常大的结果集,占用大量内存。 如果你对内存比较敏感,那么你可以使用生成器表达式迭代产生过滤的元素。比如:
>>> pos = (n for n in mylist if n > 0)
>>> pos
<generator object <genexpr> at 0x1006a0eb0>
>>> for x in pos:
... print(x)
列表推导和生成器表达式通常情况下是过滤数据最简单的方式。 其实它们还能在过滤的时候转换数据。比如:
>>> mylist = [1, 4, -5, 10, -7, 2, 3, -1]
>>> import math
>>> [math.sqrt(n) for n in mylist if n > 0]
[1.0, 2.0, 3.1622776601683795, 1.4142135623730951, 1.7320508075688772]
过滤操作的一个变种就是将不符合条件的值用新的值代替,而不是丢弃它们。 比如,在一列数据中你可能不仅想找到正数,而且还想将不是正数的数替换成指定的数。 通过将过滤条件放到条件表达式中去,可以很容易的解决这个问题,就像这样:
>>> clip_neg = [n if n > 0 else 0 for n in mylist]
>>> clip_neg
[1, 4, 0, 10, 0, 2, 3, 0]
>>> clip_pos = [n if n < 0 else 0 for n in mylist]
>>> clip_pos
[0, 0, -5, 0, -7, 0, 0, -1]
转换并同时计算数据
一个非常优雅的方式去结合数据计算与转换就是使用一个生成器表达式参数。 比如,如果你想计算平方和,可以像下面这样做:
nums = [1, 2, 3, 4, 5]
s = sum(x * x for x in nums)
使用一个生成器表达式作为参数会比先创建一个临时列表更加高效和优雅。 比如,如果你不使用生成器表达式的话,你可能会考虑使用下面的实现方式:
nums = [1, 2, 3, 4, 5]
s = sum([x * x for x in nums])
这种方式同样可以达到想要的效果,但是它会多一个步骤,先创建一个额外的列表。 对于小型列表可能没什么关系,但是如果元素数量非常大的时候, 它会创建一个巨大的仅仅被使用一次就被丢弃的临时数据结构。而生成器方案会以迭代的方式转换数据,因此更省内存。
字符串开头或结尾匹配
检查字符串开头或结尾的一个简单方法是使用 str.startswith() 或者是 str.endswith() 方法。比如:
>>> filename = 'spam.txt'
>>> filename.endswith('.txt')
True
>>> filename.startswith('file:')
False
>>> url = 'http://www.python.org'
>>> url.startswith('http:')
True
如果你想检查多种匹配可能,只需要将所有的匹配项放入到一个元组中去, 然后传给 startswith() 或者 endswith() 方法:
filenames
[ 'Makefile', 'foo.c', 'bar.py', 'spam.c', 'spam.h' ]
>>> [name for name in filenames if name.endswith(('.c', '.h')) ]
['foo.c', 'spam.c', 'spam.h'
>>> any(name.endswith('.py') for name in filenames)
True
下面是另一个例子:
from urllib.request import urlopen
def read_data(name):
if name.startswith(('http:', 'https:', 'ftp:')):
return urlopen(name).read()
else:
with open(name) as f:
return f.read()
奇怪的是,这个方法中必须要输入一个元组作为参数。 如果你恰巧有一个 list 或者 set 类型的选择项, 要确保传递参数前先调用 tuple() 将其转换为元组类型。
数组运算
>>> # Python lists
>>> x = [1, 2, 3, 4]
>>> y = [5, 6, 7, 8]
>>> x * 2
[1, 2, 3, 4, 1, 2, 3, 4]
>>> x + 10
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can only concatenate list (not "int") to list
>>> x + y
[1, 2, 3, 4, 5, 6, 7, 8]
>>> # Numpy arrays
>>> import numpy as np
>>> ax = np.array([1, 2, 3, 4])
>>> ay = np.array([5, 6, 7, 8])
>>> ax * 2
array([2, 4, 6, 8])
>>> ax + 10
array([11, 12, 13, 14])
>>> ax + ay
array([ 6, 8, 10, 12])
>>> ax * ay
array([ 5, 12, 21, 32])
迭代器与生成器
在使用Python的过程中,经常会和列表/元组/字典(list/tuple/dict)、容器(container)、可迭代对象(iterable)、迭代器(iterator)、生成器(generator)等这些名词打交道,众多的概念掺杂到一起难免会让人一头雾水,这里我们用一张图来展现它们之间的关系。
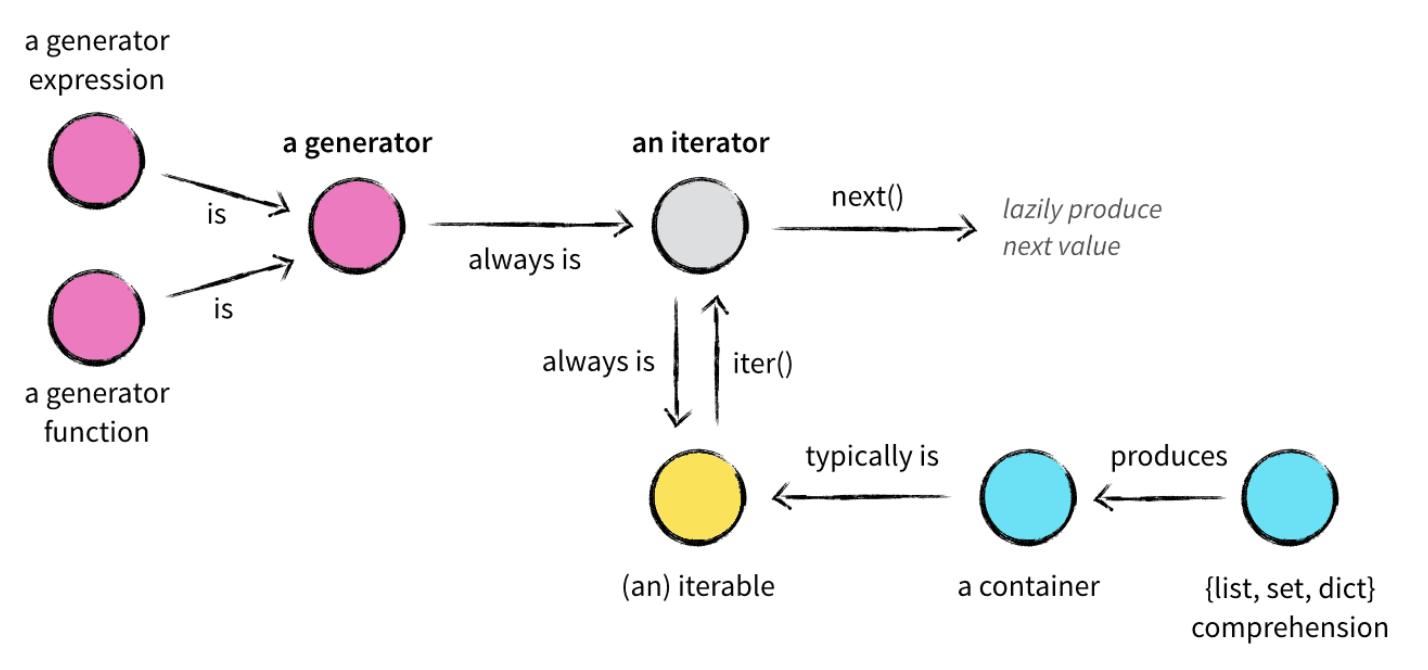
容器是一种把多个元素组织在一起的数据结构,容器中的元素可以逐个迭代获取,可以用 in,not in 关键字判断元素是否包含在容器中。通常这类数据结构把所有的元素存储在内存中(也有一些特例,并不是所有的元素都放在内存,比如迭代器和生成器对象),我们常用的 string、set、list、tuple、dict 都属于容器对象。
迭代器基本内容
迭代器是一个带状态的对象,它能在你调用next()方法时返回容器中的下一个值,任何实现了__iter__()和__next__()(Python2.x中实现next())方法的对象都是迭代器,iter()返回迭代器自身,next()返回容器中的下一个值,如果容器中没有更多元素了,则抛出StopIteration异常。
迭代器:
>>> a = (i for i in range(10))
>>> print(a)
<generator object <genexpr> at 0x10cdbc970>
>>> print(next(a))
0
>>> print(next(a))
1
为了手动的遍历可迭代对象,使用 next() 函数并在代码中捕获 StopIteration 异常。 比如,下面的例子手动读取一个文件中的所有行:
def manual_iter():
with open('/etc/passwd') as f:
try:
while True:
line = next(f)
print(line, end='')
except StopIteration:
pass
通常来讲, StopIteration 用来指示迭代的结尾。 然而,如果你手动使用上面演示的 next() 函数的话,你还可以通过返回一个指定值来标记结尾,比如 None 。 下面是示例:
with open('/etc/passwd') as f:
while True:
line = next(f, None)
if line is None:
break
print(line, end='')
迭代器与列表的区别在于,构建迭代器的时候,不像列表把所有元素一次性加载到内存,而是以一种延迟计算(lazy evaluation)方式返回元素,这正是它的优点。比如列表中含有一千万个整数,需要占超过100M的内存,而迭代器只需要几十个字节的空间。因为它并没有把所有元素装载到内存中,而是等到调用next()方法的时候才返回该元素(按需调用 call by need 的方式,本质上 for 循环就是不断地调用迭代器的next()方法)。
itertools模块里的函数返回的都是迭代器对象。为了更直观的感受迭代器内部的执行过程,我们自定义一个迭代器,以斐波那契数列为例:
class Fib(object):
def __init__(self, max=0):
super(Fib, self).__init__()
self.prev = 0
self.curr = 1
self.max = max
def __iter__(self):
return self
def __next__(self):
if self.max > 0:
self.max -= 1
# 当前要返回的元素的值
value = self.curr
# 下一个要返回的元素的值
self.curr += self.prev
# 设置下一个元素的上一个元素的值
self.prev = value
return value
else:
raise StopIteration
# 兼容Python2.x
def next(self):
return self.__next__()
if __name__ == '__main__':
fib = Fib(10)
# 调用next()的过程
for n in fib:
print(n)
# raise StopIteration
print(next(fib))
生成器基本内容
了解了迭代器之后,我们来看下生成器,普通函数用return返回一个值,还有一种函数用yield返回值,这种函数叫生成器函数。函数被调用时会返回一个生成器对象。生成器其实是一种特殊的迭代器,不过这种迭代器更加优雅,它不需要像普通迭代器一样实现__iter__()和__next__()方法了,只需要一个yield关键字。生成器一定是迭代器(反之不成立),因此任何生成器也是一种懒加载的模式生成值。下面来用生成器来实现斐波那契数列的例子:
def fib(max):
prev, curr = 0, 1
while max > 0:
max -= 1
yield curr
prev, curr = curr, prev + curr
if __name__ == '__main__':
fib = fib(6)
# 调用next()的过程
for n in fib:
print(n)
# raise StopIteration
print(next(fib))
上面是生成器函数,再来看下生成器的表达式,生成器表达式是列表推导式的生成器版本,看起来像列表推导式,但是它返回的是一个生成器对象而不是列表对象。
>>> x = (x*x for x in range(10))
>>> type(x)
<class 'generator'>
>>> y = [x*x for x in range(10)]
>>> type(y)
<class 'list'>
yield就是return返回一个值,并且记住这个返回的位置,下次迭代就从这个位置后(下一行)开始。next方法和send方法都可以返回下一个元素,区别在于send可以传递参数给yield表达式,这时传递的参数会作为yield表达式的值,而yield的参数是返回给调用者的值。
总结:
- 可迭代对象(Iterable)是实现了__iter__()方法的对象,通过调用iter()方法可以获得一个迭代器(Iterator)。
- 迭代器(Iterator)是实现了__iter__()方法和__next()__方法的对象。
- for...in...的迭代实际是将可迭代对象转换成迭代器,再重复调用next()方法实现的。
- 生成器(Generator)是一个特殊的迭代器,它的实现更简单优雅。
- yield是生成器实现__next__()方法的关键。它作为生成器执行的暂停恢复点,可以对yield表达式进行赋值,也可以将yield表达式的值返回。
代理迭代
实际上你只需要定义一个 __iter__() 方法,将迭代操作代理到容器内部的对象上去。比如:
class Node:
def __init__(self, value):
self._value = value
self._children = []
def __repr__(self):
return 'Node({!r})'.format(self._value)
def add_child(self, node):
self._children.append(node)
def __iter__(self):
return iter(self._children)
# Example
if __name__ == '__main__':
root = Node(0)
child1 = Node(1)
child2 = Node(2)
root.add_child(child1)
root.add_child(child2)
# Outputs Node(1), Node(2)
for ch in root:
print(ch)
在上面代码中, __iter__() 方法只是简单的将迭代请求传递给内部的 _children 属性。
使用生成器创建新的迭代模式
如果你想实现一种新的迭代模式,使用一个生成器函数来定义它。 下面是一个生产某个范围内浮点数的生成器:
def frange(start, stop, increment):
x = start
while x < stop:
yield x
x += increment
为了使用这个函数, 你可以用for循环迭代它或者使用其他接受一个可迭代对象的函数(比如 sum() , list() 等)。示例如下:
>>> for n in frange(0, 2, 0.5):
... print(n)
...
0
0.5
1.0
1.5
>>> list(frange(0, 1, 0.125))
[0, 0.125, 0.25, 0.375, 0.5, 0.625, 0.75, 0.875]
一个函数中需要有一个 yield 语句即可将其转换为一个生成器。 跟普通函数不同的是,生成器只能用于迭代操作。下面是一个实验,展示这样的函数底层工作机制:
>>> def countdown(n):
... print('Starting to count from', n)
... while n > 0:
... yield n
... n -= 1
... print('Done!')
...
>>> # Create the generator, notice no output appears
>>> c = countdown(2)
>>> c
<generator object countdown at 0x1006a0af0>
>>> # Run to first yield and emit a value
>>> next(c)
Starting to count from 2
2
>>> # Run to next yield
>>> next(c)
1
>>> # Run to next yield (iteration stops)
>>> next(c)
Done!
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
>>>
反向迭代
很多程序员并不知道可以通过在自定义类上实现 __reversed__() 方法来实现反向迭代。比如:
class Countdown:
def __init__(self, start):
self.start = start
# Forward iterator
def __iter__(self):
n = self.start
while n > 0:
yield n
n -= 1
# Reverse iterator
def __reversed__(self):
n = 1
while n <= self.start:
yield n
n += 1
for rr in reversed(Countdown(30)):
print(rr)
for rr in Countdown(30):
print(rr)
定义一个反向迭代器可以使得代码非常的高效, 因为它不再需要将数据填充到一个列表中然后再去反向迭代这个列表。
文件与IO
读写文本文件数据
读写文本文件一般来讲是比较简单的。但是也几点是需要注意的。 首先,在例子程序中的with语句给被使用到的文件创建了一个上下文环境, 但 with 控制块结束时,文件会自动关闭。也可以不使用 with 语句,但是这时候就必须记得手动关闭文件:
f = open('somefile.txt', 'rt')
data = f.read()
f.close()
另外一个问题是关于换行符的识别问题,在Unix和Windows中是不一样的(分别是n和rn)。 默认情况下,Python会以统一模式处理换行符。 这种模式下,在读取文本的时候,Python可以识别所有的普通换行符并将其转换为单个 \n 字符。 类似的,在输出时会将换行符 \n 转换为系统默认的换行符。 如果你不希望这种默认的处理方式,可以给 open() 函数传入参数 newline='' ,就像下面这样:
# Read with disabled newline translation
with open('somefile.txt', 'rt', newline='') as f:
...
为了说明两者之间的差异,下面我在Unix机器上面读取一个Windows上面的文本文件,里面的内容是 hello world!\r\n :
>>> # Newline translation enabled (the default)
>>> f = open('hello.txt', 'rt')
>>> f.read()
'hello world!\n'
>>> # Newline translation disabled
>>> g = open('hello.txt', 'rt', newline='')
>>> g.read()
'hello world!\r\n'
最后一个问题就是文本文件中可能出现的编码错误。 但你读取或者写入一个文本文件时,你可能会遇到一个编码或者解码错误。比如:
>>> f = open('sample.txt', 'rt', encoding='ascii')
>>> f.read()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.3/encodings/ascii.py", line 26, in decode
return codecs.ascii_decode(input, self.errors)[0]
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position
12: ordinal not in range(128)
如果出现这个错误,通常表示你读取文本时指定的编码不正确。 你最好仔细阅读说明并确认你的文件编码是正确的(比如使用UTF-8而不是Latin-1编码或其他)。 如果编码错误还是存在的话,你可以给 open() 函数传递一个可选的 errors 参数来处理这些错误。 下面是一些处理常见错误的方法:
>>> # Replace bad chars with Unicode U+fffd replacement char
>>> f = open('sample.txt', 'rt', encoding='ascii', errors='replace')
>>> f.read()
'Spicy Jalape?o!'
>>> # Ignore bad chars entirely
>>> g = open('sample.txt', 'rt', encoding='ascii', errors='ignore')
>>> g.read()
'Spicy Jalapeo!'
打印输出至文件中
在 print() 函数中指定 file 关键字参数,像下面这样:
with open('d:/work/test.txt', 'wt') as f:
print('Hello World!', file=f)
关于输出重定向到文件中就这些了。但是有一点要注意的就是文件必须是以文本模式打开。 如果文件是二进制模式的话,打印就会出错。
文件不存在才能写入
可以在 open() 函数中使用 x 模式来代替 w 模式的方法来解决这个问题。比如:
>>> with open('somefile', 'wt') as f:
... f.write('Hello\n')
...
>>> with open('somefile', 'xt') as f:
... f.write('Hello\n')
...
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
FileExistsError: [Errno 17] File exists: 'somefile'
如果文件是二进制的,使用 xb 来代替 xt。
字符串的I/O操作
使用 io.StringIO() 和 io.BytesIO() 类来创建类文件对象操作字符串数据。比如:
>>> s = io.StringIO()
>>> s.write('Hello World\n')
12
>>> print('This is a test', file=s)
15
>>> # Get all of the data written so far
>>> s.getvalue()
'Hello World\nThis is a test\n'
>>>
>>> # Wrap a file interface around an existing string
>>> s = io.StringIO('Hello\nWorld\n')
>>> s.read(4)
'Hell'
>>> s.read()
'o\nWorld\n'
io.StringIO 只能用于文本。如果你要操作二进制数据,要使用 io.BytesIO 类来代替。比如:
>>> s = io.BytesIO()
>>> s.write(b'binary data')
>>> s.getvalue()
b'binary data'
读写压缩文件
gzip 和 bz2 模块可以很容易的处理这些文件。 两个模块都为 open() 函数提供了另外的实现来解决这个问题。 比如,为了以文本形式读取压缩文件,可以这样做:
# gzip compression
import gzip
with gzip.open('somefile.gz', 'rt') as f:
text = f.read()
# bz2 compression
import bz2
with bz2.open('somefile.bz2', 'rt') as f:
text = f.read()
类似的,为了写入压缩数据,可以这样做:
# gzip compression
import gzip
with gzip.open('somefile.gz', 'wt') as f:
f.write(text)
# bz2 compression
import bz2
with bz2.open('somefile.bz2', 'wt') as f:
f.write(text)
如上,所有的I/O操作都使用文本模式并执行Unicode的编码/解码。 类似的,如果你想操作二进制数据,使用 rb 或者 wb 文件模式即可。
大部分情况下读写压缩数据都是很简单的。但是要注意的是选择一个正确的文件模式是非常重要的。 如果你不指定模式,那么默认的就是二进制模式,如果这时候程序想要接受的是文本数据,那么就会出错。 gzip.open() 和 bz2.open() 接受跟内置的 open() 函数一样的参数, 包括 encoding,errors,newline 等等。
zip压缩文件的读写方法:Python中读取ZIP文件
函数
类与函数
区别主要在于类可以在执行时存储一些信息,以便于在重复调用时使用这些存储的内容。比如:
>>> def print_result(result):
... print('Got:', result)
class ResultHandler:
def __init__(self):
self.sequence = 0
def handler(self, result):
self.sequence += 1
print('[{}] Got: {}'.format(self.sequence, result))
使用这个类的时候,你先创建一个类的实例,然后用它的 handler() 绑定方法来做为回调函数:
>>> r = ResultHandler()
>>> apply_async(add, (2, 3), callback=r.handler)
[1] Got: 5
>>> apply_async(add, ('hello', 'world'), callback=r.handler)
[2] Got: helloworld
当然,用yield也能完成同样的事情:
def make_handler():
sequence = 0
while True:
result = yield
sequence += 1
print('[{}] Got: {}'.format(sequence, result))
所以,从上面就可以看出,对于一个大型程序所需输出/存储的log信息,可以创建一个类来完成。
参数
Python函数的参数可以分为默认参数,位置参数,关键字参数,可变参数。函数可以没有参数,也可以有多个参数。
- 形参:定义函数时的参数,如定义函数def func(a,b)的参数a,b是形参。
- 实参:调用函数时参数的值,如调用函数func(2,3)的参数2,3是实参。
- 默认参数:定义函数时,为形参提供默认值,默认参数必须在最右端。 调用函数的时候如果没有传入实参,则取默认参数。如果传入实参,则取实参。
- 位置参数:调用函数时传入实际参数的数量和位置都必须和定义函数时保持一致。
- 关键字参数:调用函数的时候使用的是键值对的方式,key=values。混合传参时关键字参数必须在位置参数之后,调用函数 function add 时提供关键字参数。
print(add(10,c=30,b=20))
# 10为位置参数,c=30和b=20为关键字参数。
装饰器
@是一个装饰器,针对函数,起调用传参的作用。有修饰和被修饰的区别,@function作为一个装饰器,用来修饰紧跟着的函数(可以是另一个装饰器,也可以是函数定义)。
例子1:
def funA(desA):
print('It\'s funA')
def funB(desB):
print('It\'s funB')
@funA
def funC():
print('It\'s funC')
执行结果:
It's funA
分析:@funA 修饰函数定义def funC(),将funC()赋值给funA()的形参。执行的时候由上而下,先定义funA、funB,然后运行funA(funC())。此时desA=funC(),然后funA()输出‘It's funA'。
例子2:
def funA(desA):
print('It\'s funA')
def funB(desB):
print('It\'s funB')
@funB
@funA
def funC():
print('It\'s funC')
执行结果:
It's funA
It's funB
分析:@funB 修饰装饰器@funA,@funA 修饰函数定义def funC(),将funC()赋值给funA()的形参,再将funA(funC())赋值给funB()。执行的时候由上而下,先定义funA、funB,然后运行funB(funA(funC()))。此时desA=funC(),然后funA()输出‘It's funA';desB=funA(funC()),然后funB()输出‘It's funB'。
def funA(desA):
print('It\'s funA')
print('---')
print(desA)
desA()
print('---')
def funB(desB):
print('It\'s funB')
@funB
@funA
def funC():
print('It\'s funC')
执行结果:
It's funA
---
<function funC at 0x10bcdf9d0>
It's funC
---
It's funB
分析:同上,为了更直观地看参数传递,打印desA,其传的是funC()的地址,即desA现在为函数desA()。 执行desA()即执行funC(),desA=desA()=funC()。
可接受任意数量参数的函数
为了能让一个函数接受任意数量的位置参数,可以使用一个*参数。例如:
def avg(first, *rest):
return (first + sum(rest)) / (1 + len(rest))
# Sample use
avg(1, 2) # 1.5
avg(1, 2, 3, 4) # 2.5
在这个例子中,rest是由所有其他位置参数组成的元组。然后我们在代码中把它当成了一个序列来进行后续的计算。
为了接受任意数量的关键字参数,使用一个以**开头的参数。比如:
import html
def make_element(name, value, **attrs):
keyvals = [' %s="%s"' % item for item in attrs.items()]
attr_str = ''.join(keyvals)
element = '<{name}{attrs}>{value}</{name}>'.format(
name=name,
attrs=attr_str,
value=html.escape(value))
return element
# Example
# Creates '<item size="large" quantity="6">Albatross</item>'
make_element('item', 'Albatross', size='large', quantity=6)
# Creates '<p><spam></p>'
make_element('p', '<spam>')
在这里,attrs是一个包含所有被传入进来的关键字参数的字典。
如果你还希望某个函数能同时接受任意数量的位置参数和关键字参数,可以同时使用*和**。比如:
def anyargs(*args, **kwargs):
print(args) # A tuple
print(kwargs) # A dict
使用这个函数时,所有位置参数会被放到args元组中,所有关键字参数会被放到字典kwargs中。
一个*参数只能出现在函数定义中最后一个位置参数后面,而**参数只能出现在最后一个参数。 有一点要注意的是,在*参数后面仍然可以定义其他参数。
def a(x, *args, y):
pass
def b(x, *args, y, **kwargs):
pass
只接受关键字参数的函数
将强制关键字参数放到某个参数或者单个后面就能达到这种效果。比如:
def recv(maxsize, *, block):
'Receives a message'
pass
recv(1024, True) # TypeError
recv(1024, block=True) # Ok
利用这种技术,我们还能在接受任意多个位置参数的函数中指定关键字参数。比如:
def mininum(*values, clip=None):
m = min(values)
if clip is not None:
m = clip if clip > m else m
return m
minimum(1, 5, 2, -5, 10) # Returns -5
minimum(1, 5, 2, -5, 10, clip=0) # Returns 0
很多情况下,使用强制关键字参数会比使用位置参数表意更加清晰,程序也更加具有可读性。 例如,考虑下如下一个函数调用:
msg = recv(1024, False)
如果调用者对recv函数并不是很熟悉,那他肯定不明白那个False参数到底来干嘛用的。 但是,如果代码变成下面这样子的话就清楚多了:
msg = recv(1024, block=False)
另外,使用强制关键字参数也会比使用**kwargs参数更好,因为在使用函数help的时候输出也会更容易理解:
>>> help(recv)
Help on function recv in module __main__:
recv(maxsize, *, block)
Receives a message
强制关键字参数在一些更高级场合同样也很有用。 例如,它们可以被用来在使用*args和**kwargs参数作为输入的函数中插入参数。
减少可调用对象的参数个数
如果需要减少某个函数的参数个数,你可以使用 functools.partial() 。 partial() 函数允许你给一个或多个参数设置固定的值,减少接下来被调用时的参数个数。 为了演示清楚,假设你有下面这样的函数:
def spam(a, b, c, d):
print(a, b, c, d)
现在我们使用 partial() 函数来固定某些参数值:
>>> from functools import partial
>>> s1 = partial(spam, 1) # a = 1
>>> s1(2, 3, 4)
1 2 3 4
>>> s1(4, 5, 6)
1 4 5 6
>>> s2 = partial(spam, d=42) # d = 42
>>> s2(1, 2, 3)
1 2 3 42
>>> s2(4, 5, 5)
4 5 5 42
>>> s3 = partial(spam, 1, 2, d=42) # a = 1, b = 2, d = 42
>>> s3(3)
1 2 3 42
>>> s3(5)
1 2 5 42
可以看出 partial() 固定某些参数并返回一个新的callable对象。这个新的callable接受未赋值的参数, 然后跟之前已经赋值过的参数合并起来,最后将所有参数传递给原始函数。
假设你有一个点的列表来表示(x,y)坐标元组。 你可以使用下面的函数来计算两点之间的距离:
points = [ (1, 2), (3, 4), (5, 6), (7, 8) ]
import math
def distance(p1, p2):
x1, y1 = p1
x2, y2 = p2
return math.hypot(x2 - x1, y2 - y1)
现在假设你想以某个点为基点,根据点和基点之间的距离来排序所有的这些点。 列表的 sort() 方法接受一个关键字参数来自定义排序逻辑, 但是它只能接受一个单个参数的函数(distance()很明显是不符合条件的)。 现在我们可以通过使用 partial() 来解决这个问题:
>>> pt = (4, 3)
>>> points.sort(key=partial(distance,pt))
>>> points
[(3, 4), (1, 2), (5, 6), (7, 8)]
类与对象
改变对象的字符串显示
要改变一个实例的字符串表示,可重新定义它的 __str__() 和 __repr__() 方法。例如:
class Pair:
def __init__(self, x, y):
self.x = x
self.y = y
def __repr__(self):
return 'Pair({0.x!r}, {0.y!r})'.format(self)
def __str__(self):
return '({0.x!s}, {0.y!s})'.format(self)
__repr__() 方法返回一个实例的代码表示形式,通常用来重新构造这个实例。 内置的 repr() 函数返回这个字符串,跟我们使用交互式解释器显示的值是一样的。 __str__() 方法将实例转换为一个字符串,使用 str() 或 print() 函数会输出这个字符串。比如:
>>> p = Pair(3, 4)
>>> p
Pair(3, 4) # __repr__() output
>>> print(p)
(3, 4) # __str__() output
我们在这里还演示了在格式化的时候怎样使用不同的字符串表现形式。 特别来讲,!r 格式化代码指明输出使用 __repr__() 来代替默认的 __str__() 。 你可以用前面的类来试着测试下:
>>> p = Pair(3, 4)
>>> print('p is {0!r}'.format(p))
p is Pair(3, 4)
>>> print('p is {0}'.format(p))
p is (3, 4)
自定义 __repr__() 和 __str__() 通常是很好的习惯,因为它能简化调试和实例输出。 例如,如果仅仅只是打印输出或日志输出某个实例,那么程序员会看到实例更加详细与有用的信息。
__repr__() 生成的文本字符串标准做法是需要让 eval(repr(x)) == x 为真。 如果实在不能这样子做,应该创建一个有用的文本表示,并使用 < 和 > 括起来。比如:
>>> f = open('file.dat')
>>> f
<_io.TextIOWrapper name='file.dat' mode='r' encoding='UTF-8'>
如果 __str__() 没有被定义,那么就会使用 __repr__() 来代替输出。
上面的 format() 方法的使用看上去很有趣,格式化代码 {0.x} 对应的是第1个参数的x属性。 因此,在下面的函数中,0实际上指的就是 self 本身:
def __repr__(self):
return 'Pair({0.x!r}, {0.y!r})'.format(self)
作为这种实现的一个替代,你也可以使用 % 操作符,就像下面这样:
def __repr__(self):
return 'Pair(%r, %r)' % (self.x, self.y)
让对象支持上下文管理协议(with)
为了让一个对象兼容 with 语句,你需要实现 __enter__() 和 __exit__() 方法。 例如,考虑如下的一个类,它能为我们创建一个网络连接:
from socket import socket, AF_INET, SOCK_STREAM
class LazyConnection:
def __init__(self, address, family=AF_INET, type=SOCK_STREAM):
self.address = address
self.family = family
self.type = type
self.sock = None
def __enter__(self):
if self.sock is not None:
raise RuntimeError('Already connected')
self.sock = socket(self.family, self.type)
self.sock.connect(self.address)
return self.sock
def __exit__(self, exc_ty, exc_val, tb):
self.sock.close()
self.sock = None
这个类的关键特点在于它表示了一个网络连接,但是初始化的时候并不会做任何事情(比如它并没有建立一个连接)。 连接的建立和关闭是使用 with 语句自动完成的,例如:
from functools import partial
conn = LazyConnection(('www.python.org', 80))
# Connection closed
with conn as s:
# conn.__enter__() executes: connection open
s.send(b'GET /index.html HTTP/1.0\r\n')
s.send(b'Host: www.python.org\r\n')
s.send(b'\r\n')
resp = b''.join(iter(partial(s.recv, 8192), b''))
# conn.__exit__() executes: connection closed
编写上下文管理器的主要原理是你的代码会放到 with 语句块中执行。 当出现 with 语句的时候,对象的 __enter__() 方法被触发, 它返回的值(如果有的话)会被赋值给 as 声明的变量。然后,with 语句块里面的代码开始执行。 最后,__exit__() 方法被触发进行清理工作。
不管 with 代码块中发生什么,上面的控制流都会执行完,就算代码块中发生了异常也是一样的。 事实上,__exit__() 方法的第三个参数包含了异常类型、异常值和追溯信息(如果有的话)。 __exit__() 方法能自己决定怎样利用这个异常信息,或者忽略它并返回一个None值。 如果 __exit__() 返回 True ,那么异常会被清空,就好像什么都没发生一样, with 语句后面的程序继续在正常执行。
创建大量对象时节省内存方法
对于主要是用来当成简单的数据结构的类而言,你可以通过给类添加 __slots__ 属性来极大的减少实例所占的内存。比如:
class Date:
__slots__ = ['year', 'month', 'day']
def __init__(self, year, month, day):
self.year = year
self.month = month
self.day = day
当你定义 __slots__ 后,Python就会为实例使用一种更加紧凑的内部表示。 实例通过一个很小的固定大小的数组来构建,而不是为每个实例定义一个字典,这跟元组或列表很类似。 在 __slots__ 中列出的属性名在内部被映射到这个数组的指定小标上。 使用slots一个不好的地方就是我们不能再给实例添加新的属性了,只能使用在 __slots__ 中定义的那些属性名。
使用slots后节省的内存会跟存储属性的数量和类型有关。 不过,一般来讲,使用到的内存总量和将数据存储在一个元组中差不多。 为了给你一个直观认识,假设你不使用slots直接存储一个Date实例, 在64位的Python上面要占用428字节,而如果使用了slots,内存占用下降到156字节。 如果程序中需要同时创建大量的日期实例,那么这个就能极大的减小内存使用量了。
尽管slots看上去是一个很有用的特性,很多时候你还是得减少对它的使用冲动。 Python的很多特性都依赖于普通的基于字典的实现。 另外,定义了slots后的类不再支持一些普通类特性了,比如多继承。 大多数情况下,你应该只在那些经常被使用到的用作数据结构的类上定义slots (比如在程序中需要创建某个类的几百万个实例对象)。
关于 __slots__ 的一个常见误区是它可以作为一个封装工具来防止用户给实例增加新的属性。 尽管使用slots可以达到这样的目的,但是这个并不是它的初衷。 __slots__ 更多的是用来作为一个内存优化工具。