
SQL学习笔记
有了大语言模型之后,学习和应用一个陌生的代码框架真的容易了太多,这样算法工程师就可以把更多心思放在如何设计算法上,用我个人今天的经验举个例子:
简单应用
下午15点左右,接到了一个任务,有一个数据库,其中关键信息为uid、aid、ts,分别为user用户id、author作者id、timestamp时间戳,需求:1.只保留一个ts下的数据,2.相同的(uid,aid)对,只保留一条数据。在此之前我没接触过SQL,但是,通过kimi:
任务一:筛选
提示
Prompt:写一段sql语句,用于从一个表格中读取ts列以及新的一列rk,rk列内容为ts从小到大排列的位次。
为什么这样实现?由于我们并不能直接写死筛选某个特殊的ts值,所以最好的方式是将ts排序,形成新的一列:rank,然后通过rank列的数值进行筛选。
kimi:
在SQL中,您可以使用RANK()函数来实现行的排名。RANK()函数会根据您指定的列的值进行排序,并为每一行分配一个唯一的排名。如果存在相同的值,则这些行会获得相同的排名,并且下一个排名会跳过一个数字。例如,如果两行都排名第一,则下一个排名会直接是第三。
以下是一段SQL语句,用于从一个名为your_table的表格中读取ts列,并添加一个新的列rk,其中rk列是ts列值从小到大排列的位次:
SELECT ts, RANK() OVER (ORDER BY ts) AS rk
FROM your_table;
这里使用的OVER子句指定了RANK()函数的排序依据,即按照ts列的值从小到大排序。如果ts列中有相同的值,它们将获得相同的排名,并且排名不会有间隔。
如果您希望即使在有相同值的情况下排名也不跳过数字(即连续排名),可以使用DENSE_RANK()函数替代RANK():
SELECT ts, DENSE_RANK() OVER (ORDER BY ts) AS rk
FROM your_table;
这将保证即使ts列中有相同的值,排名也是连续的。
任务二:去重
提示
Prompt:写一段sql语句,用于从一个表格中读取uid、aid两个字段,并去除具有相同uid和aid的行
kimi:
要从一个表中读取 uid 和 aid 字段,并且去除具有相同 uid 和 aid 的重复行,可以使用 GROUP BY 语句结合聚合函数来实现。以下是一个示例 SQL 语句:
SELECT uid, aid
FROM original_table
GROUP BY uid, aid;
这段 SQL 语句的作用是:
SELECT uid, aid指定了要查询的字段。FROM original_table指定了查询的表,你需要将original_table替换为实际的表名。GROUP BY uid, aid将结果按照uid和aid进行分组,这样每个uid和aid的组合只会在结果集中出现一次,从而去除重复行。
如果你需要将这个结果插入到一个新的表中,可以使用 INSERT INTO 语句,如下所示:
CREATE TABLE new_table AS
SELECT uid, aid
FROM original_table
GROUP BY uid, aid;
这个语句首先创建了一个新的表 new_table,然后通过 SELECT 语句查询去重后的数据,并将结果插入到新表中。记得根据你的数据库环境和表结构调整这些语句。
聚合代码
-- 如果存在名为 reco_live.a2u_live_author_tmp_0613_yih 的表,则删除该表
drop table if exists reco_live.a2u_live_author_tmp_0613_yih;
-- 创建一个新表 reco_live.a2u_live_author_tmp_0613_yih,如果表不存在的话
-- 同时设置表属性,指定数据的生命周期为7天
create table if not exists reco_live.a2u_live_author_tmp_0613_yih
tblproperties('kuaishou.dp-mdc.lifecycle.day' = '7') as
-- 选择数据的查询开始
select
uid, -- 选择拆分后的uid字段
get_json_object(json, '$.aid') as aid, -- 从json字段中提取aid
biz, -- 选择biz字段
RANK() over (order by ts) as rk -- 根据ts字段对结果进行排名
from
(
-- 子查询,从原始日志表中选择数据
select
*
from
ks_origin_reco_live_log.reco_live_rocket_general_json_log
where
p_date = '{{ds_nodash}}' -- 选择特定日期的数据,具体日期由外部变量提供
-- and p_hourmin in ('0900', '0800') -- 这行被注释掉了,原本用于选择特定时间段的数据
and biz in ('a2utask', 'a2uv2task') -- 选择特定业务类型
and get_json_object(json, '$.part') = 0 -- 选择json中part字段为0的记录
)cc
-- 使用LATERAL VIEW和posexplode函数将uid_set字段拆分成单独的行
LATERAL VIEW posexplode(split(regexp_replace(get_json_object(json, '$.uid_set'), ',', '\n'), '\n')) lateralTable AS pos, uid
-- 只选择pos小于1000的行
WHERE
pos < 1000;
完成任务!所以,人工智能的时代,会的多自然好,学的快似乎也同样重要。
任务三:统计
提示
Prompt:写一段sql代码:我有一个表,有两列:uid,num_aid,统计num_aid为1、2、3、4、5-6、7-8、9-10、11-15、15-30、>30的uid数量。
kimi:要统计不同num_aid范围内的uid数量,你可以使用CASE语句结合COUNT函数来实现:
SELECT
CASE
WHEN num_aid = 1 THEN '1'
WHEN num_aid = 2 THEN '2'
WHEN num_aid = 3 THEN '3'
WHEN num_aid = 4 THEN '4'
WHEN num_aid BETWEEN 5 AND 6 THEN '5-6'
WHEN num_aid BETWEEN 7 AND 8 THEN '7-8'
WHEN num_aid BETWEEN 9 AND 10 THEN '9-10'
WHEN num_aid BETWEEN 11 AND 15 THEN '11-15'
WHEN num_aid BETWEEN 16 AND 30 THEN '16-30'
ELSE '>30'
END AS num_aid_range,
COUNT(DISTINCT uid) AS uid_count
FROM (
SELECT
uid,
count(*) as num_aid
FROM reco_live.schedual_task_a2u_live_author_result
WHERE p_date = '20240623' AND p_hour = '2100' AND biz = 'a2utask'
group by uid
)aa
GROUP BY
CASE
WHEN num_aid = 1 THEN '1'
WHEN num_aid = 2 THEN '2'
WHEN num_aid = 3 THEN '3'
WHEN num_aid = 4 THEN '4'
WHEN num_aid BETWEEN 5 AND 6 THEN '5-6'
WHEN num_aid BETWEEN 7 AND 8 THEN '7-8'
WHEN num_aid BETWEEN 9 AND 10 THEN '9-10'
WHEN num_aid BETWEEN 11 AND 15 THEN '11-15'
WHEN num_aid BETWEEN 16 AND 30 THEN '16-30'
ELSE '>30'
END;
统计数据分位点:
SELECT
percentile(num_uid, 0.1) AS num_uid_10th_percentile,
percentile(num_uid, 0.3) AS num_uid_30th_percentile,
percentile(num_uid, 0.5) AS num_uid_50th_percentile,
percentile(num_uid, 0.8) AS num_uid_80th_percentile,
percentile(num_uid, 0.9) AS num_uid_90th_percentile,
percentile(num_uid, 0.95) AS num_uid_95th_percentile,
percentile(num_uid, 0.99) AS num_uid_99th_percentile
FROM (
SELECT
author_id,
count(*) as num_uid,
concat_ws(',',collect_set(cast(user_id as string))) as map_list
FROM reco_live.daily_user_author_action_stat_di
WHERE p_date between '20240617' and '20240623'
AND follow_author_cnt + more_60s_play_cnt + comment_cnt + send_gift_amt > 0
group by author_id
)aa;
任务四:AUC计算
AUC为正样本得分大于负样本得分的概率,但是穷举正负样本对太复杂,可以先根据得分从小到大排序,然后找出每个正样本的排序位次。计算出每个位次下负样本的个数,就是该正样本得分大于负样本得分的次数,对次数进行累加就是所有正样本得分大于负样本得分的次数,除以就是所有正样本得分大于负样本得分的概率,如下图所示:
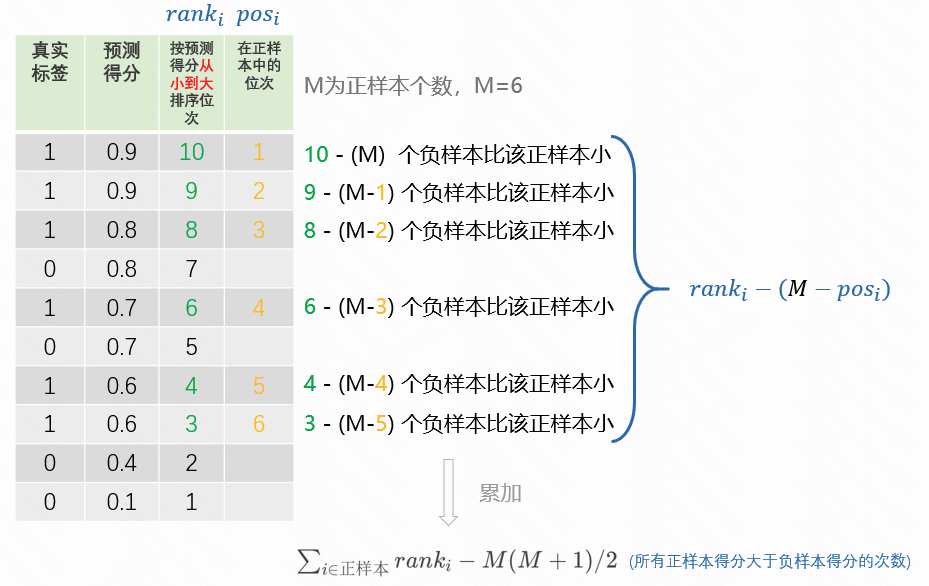
所以最终AUC的公式为:
SQL代码如下:
select
aid, (sum_rank - 0.5*m*(m+1))/n/m as auc
from(
select aid,
sum(if(y=0, 1, 0)) as n,
sum(if(y=1, 1, 0)) as m,
sum(if(y=1, r, 0)) as sum_rank
from(
select aid, pair_exists as y, row_number() over(partition by aid order by rank desc) as r
from reco_live.a2u_live_yih_auc_rank
)A group by aid
)B
sql框架
SQL 语句执行顺序:
书写顺序:SELECT -> FROM -> JOIN -> ON -> WHERE -> GROUP BY -> HAVING -> UNION -> ORDER BY ->LIMIT
执行顺序:FROM -> ON -> JOIN -> WHERE -> GROUP BY -> HAVING -> SELECT -> UNION -> ORDER BY ->LIMIT
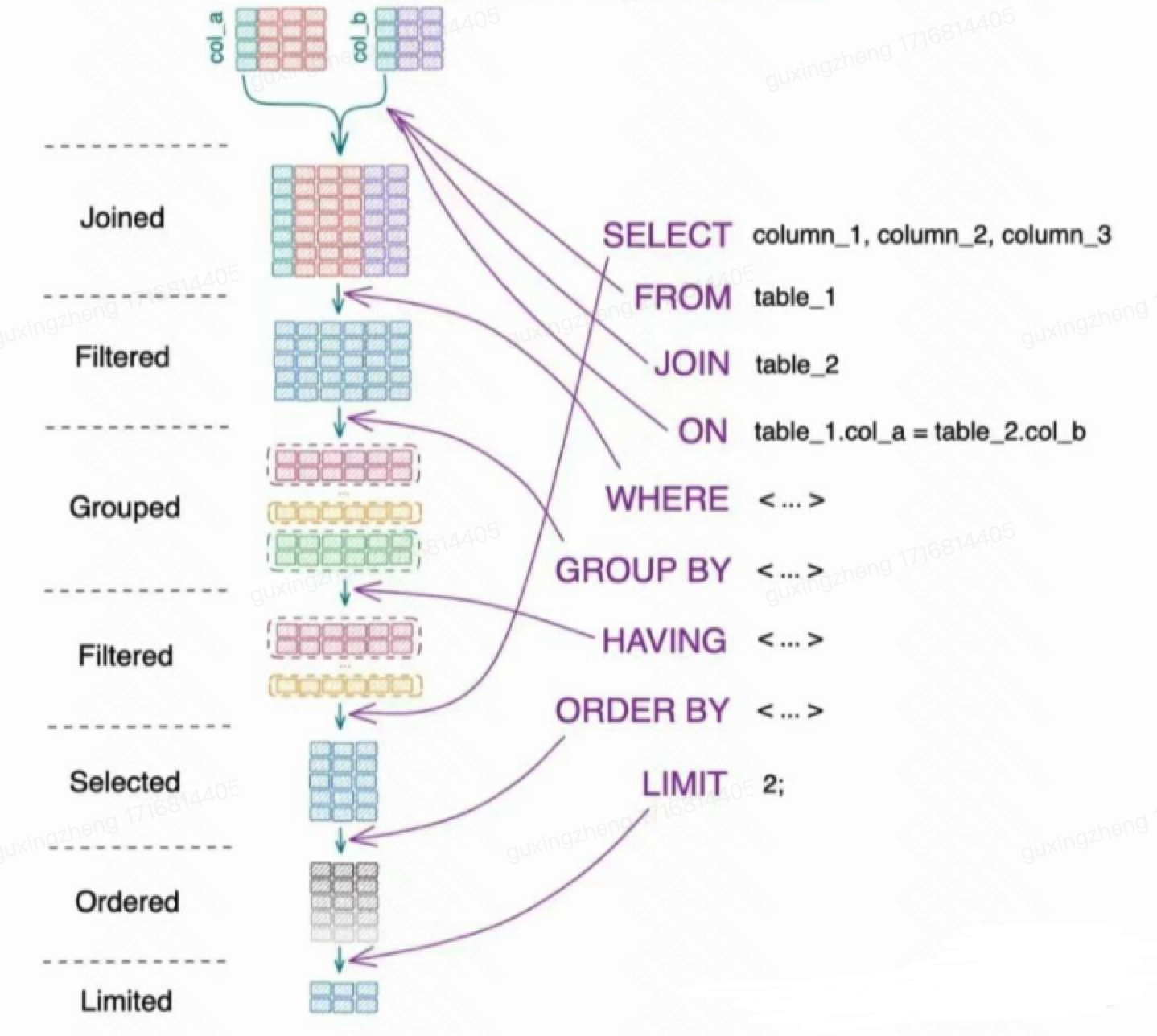
--sql的书写顺序【按行号】 执行顺序【按括号内的数字顺序】
(8) SELECT (9)DISTINCT<Select_list>
(1) FROM <left_table> (3) <join_type>JOIN<right_table>
(2) ON<join_condition>
(4) WHERE<where_condition>
(5) GROUP BY<group_by_list>
(6) WITH {CUBE|ROLLUP}
(7) HAVING<having_condtion>
(10) ORDER BY<order_by_list>
(11) LIMIT<limit_number>
参考资料
CSDN:一文学完所有的Hive Sql(两万字最全详解) 阿里云开发者社区:最强最全面的Hive SQL开发指南,超四万字全面解析 (一) CSDN:AUC的三种计算方法及代码