
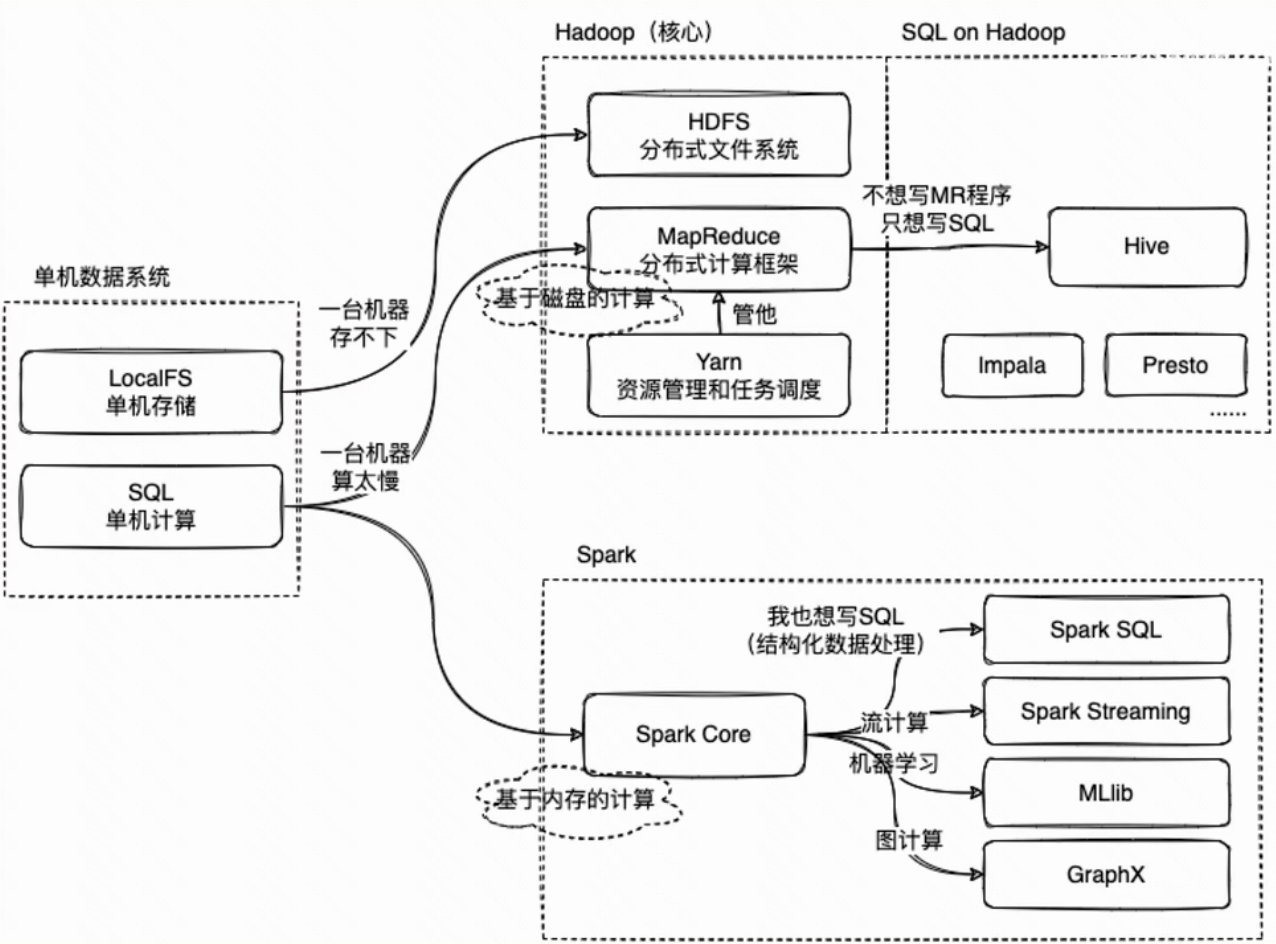
Hadoop分布式计算
Hadoop
Hadoop 是一个开源的分布式计算框架,由 Apache Software Foundation 开发和维护。它主要用于处理和分析大数据。
什么是Hadoop?
Hadoop 是一个开源的分布式计算框架,由 Apache Software Foundation 开发和维护。它主要用于处理和分析大数据。Hadoop 的核心设计理念是将计算任务分布到多个节点上,以实现高度可扩展性和容错性。
主要组件
Hadoop Distributed File System(HDFS):HDFS 是 Hadoop 的分布式文件系统,负责在集群中存储数据。HDFS 将数据切分成多个块(通常为 64MB 或 128MB),并将这些块分布到集群中的不同节点上。为了提高数据的可靠性和容错性,HDFS 会对每个数据块创建多个副本(通常为 3 个)。这样,即使某个节点发生故障,数据仍然可以从其他节点上的副本中恢复。
MapReduce 编程模型:MapReduce 是 Hadoop 的核心编程模型,用于处理和分析 HDFS 中的数据。MapReduce 任务包括两个阶段:Map 阶段和 Reduce 阶段。在 Map 阶段,输入数据被切分成多个片段,并分发到集群中的各个节点上。每个节点上的 Map 函数对其分配的数据片段进行处理,并生成一组键值对(key-value pairs)。在 Reduce 阶段,这些键值对被汇总到一个或多个 Reduce 函数中,以生成最终的输出结果。
优势
可伸缩性:Hadoop 可以在成百上千台机器之间分配和处理数据,具有很高的可伸缩性。
高可用性:Hadoop 在处理数据时具备自动故障恢复的能力。如果某一台机器出现问题,Hadoop 会自动将该节点上的数据复制到其他节点上,确保数据的可靠性和不中断性。
成本效益:与传统的大型关系数据库相比,Hadoop 成本更低,因为它运行在廉价的硬件上。
处理多种类型的数据:Hadoop 可以处理不同类型的数据,包括结构化数据和非结构化数据,例如文本、图片、视频和音频等。
高速处理大数据:Hadoop 可以高效地处理大批量的数据,因为它利用了分布式计算的优势,可以并行处理大量数据。
应用场景
批处理分析:Hadoop 可以高效地处理大量数据,广泛用于分析海量数据,如黑客入侵检测、网络日志分析、推荐系统等。
数据仓库:Hadoop 可以支持数据的多维分析和查询,而且成本低廉。许多组织将 Hadoop 用作数据仓库,数据中心或分析数据仓库。
海量存储:Hadoop 可以在廉价的硬件上存储 PB 级别的数据。Hadoop 可以实现可扩展的高吞吐量数据存储,而且具有跨机架的高可靠性。
文本挖掘:Hadoop 的 MapReduce 作业可以高效地处理文本数据,用于文本挖掘和自然语言处理。
机器学习:Hadoop 可以与机器学习工具结合使用,例如 Mahout 和 Spark 等,许多机器学习算法已经在 Hadoop 平台上实现,包括分类、回归、聚类和协同过滤等。
HDFS
什么是HDFS?
HDFS全称为Hadoop Distributed File System,是Hadoop生态系统中的一部分。HDFS是一个分布式文件系统,旨在运行于大规模数据集的分布式环境中,具有高度容错性和高度可用性。HDFS的设计目标是能够管理超大规模的数据集,支持高吞吐量数据访问,适用于部署在廉价硬件上的环境中。
HDFS主要由以下两个组件组成:
NameNode:NameNode是HDFS的主节点,负责管理文件系统的命名空间和客户端的访问请求。它维护了文件系统的目录树和文件到数据块的映射关系。
DataNode:DataNode是HDFS的从节点,负责存储和检索文件数据。它们接受来自客户端的读写请求,从本地磁盘或网络中的其他DataNode上读取或写入数据块。
文件存储原理
HDFS的文件存储原理是基于块(Block)的分布式存储。具体来说,它将大文件分成固定大小的块,通常为64MB或128MB,然后将这些块分布在不同的DataNode上,以实现数据的冗余和可靠性。块是HDFS文件系统中的最小存储单元,块的大小是固定的,可以根据具体情况进行调整。
在HDFS中,每个文件都有一个元数据,包括文件名、文件大小、块列表等信息。文件被分成多个块,每个块存储在不同的DataNode上。文件的元数据存储在NameNode上,它维护了文件系统的目录树和文件到数据块的映射关系。当客户端需要读取或写入文件时,它们将向NameNode发送请求,NameNode会返回包含文件块位置信息的列表。客户端接收到这个列表后,就可以直接从DataNode中读取或写入文件块。
为了保证数据的可靠性,HDFS使用了数据冗余技术。每个块都有多个副本,通常是3个,它们存储在不同的DataNode上,以防止某一个DataNode失效或发生故障。当一个DataNode失效时,HDFS会自动将该DataNode上的块副本复制到其他DataNode上,以实现数据的自动故障恢复。
主要特点和优势
高可靠性:HDFS采用了数据冗余和自动故障恢复等技术,保证了数据的高可靠性和数据的可靠性。
高扩展性:HDFS支持线性扩展,可以轻松地向集群中添加更多的节点,以适应不断增长的数据存储需求。
高效性:HDFS使用了块存储和数据本地化等技术,提高了数据访问的效率,使得数据的读写速度更快。
适应廉价硬件:HDFS被设计为适应低成本硬件的环境,这使得它可以在廉价的服务器上运行,并以最小的成本提供高可靠性和高性能的数据存储解决方案。
支持多种数据格式:HDFS支持多种数据格式,如文本、序列化、Avro等,适合处理不同类型的数据。
兼容性:HDFS与Hadoop生态系统的其他组件高度兼容,如MapReduce、HBase等,这使得它可以与其他组件协同工作,构建强大的数据处理和分析平台。
可定制性:HDFS支持多种配置选项,可以根据应用程序的需要进行定制,以提高性能和可靠性。
如何实现数据的分布式存储
块(Block)存储:HDFS将大文件分成固定大小的块,通常为64MB或128MB,然后将这些块分布在不同的DataNode上,以实现数据的分布式存储。块是HDFS文件系统中的最小存储单元,块的大小是固定的,可以根据具体情况进行调整。
数据本地化:HDFS的数据本地化策略可以提高数据访问的效率。在HDFS中,块可以被存储在多个DataNode上,但是它们通常与客户端距离较近的DataNode上存储,以提高数据访问的速度。
数据冗余:HDFS使用了数据冗余技术,每个块都有多个副本,通常是3个,它们存储在不同的DataNode上,以防止某一个DataNode失效或发生故障。当一个DataNode失效时,HDFS会自动将该DataNode上的块副本复制到其他DataNode上,以实现数据的自动故障恢复。
NameNode元数据:在HDFS中,每个文件都有一个元数据,包括文件名、文件大小、块列表等信息。文件的元数据存储在NameNode上,它维护了文件系统的目录树和文件到数据块的映射关系。
数据复制策略
默认的副本数:HDFS默认的数据复制副本数为3,即每个块会被复制到3个DataNode上。这个默认值可以在配置文件中进行修改,以适应不同的应用场景。
副本放置策略:HDFS会根据一定的策略将块的副本放置在不同的DataNode上。通常,一个副本会被放置在与它最近的DataNode上,而另外两个副本则会被放置在不同的机架上的DataNode上,以防止某一个机架发生故障。
副本调度策略:HDFS会定期检查每个块的副本数是否达到预设的值,如果某个块的副本数小于预设值,HDFS会自动将缺少的副本复制到其他DataNode上。副本调度策略可以保证数据的冗余和可靠性。
副本删除策略:HDFS会定期检查块的副本数是否超过预设值,如果超过了预设值,HDFS会自动删除多余的副本,以释放存储空间。副本删除策略可以保证数据的存储空间利用率。
性能优化策略
块大小:HDFS的块大小是固定的,通常为64MB或128MB。块大小的选择会影响HDFS的性能。通常来说,较大的块大小可以提高数据读取的效率,但是会增加数据本地化的难度和数据冗余的开销。
数据本地化:数据本地化是HDFS提高数据访问效率的重要手段。数据本地化可以减少数据在网络中的传输时间,提高数据读取的效率。为了实现数据本地化,可以通过增加DataNode的数量,使得数据块尽可能地存储在距离客户端最近的DataNode上。
副本数量:HDFS的数据复制副本数默认为3。增加数据复制副本数可以提高数据冗余的可靠性,但是会增加数据冗余的开销和数据复制的延迟。因此,需要根据应用场景的需要来选择数据复制副本数。
缓存:HDFS提供了缓存机制,可以将频繁访问的数据缓存在内存中,以提高数据访问的效率。缓存机制可以减少数据在磁盘上的读取次数,从而提高数据访问的速度。
压缩:HDFS支持数据压缩技术,可以将存储在HDFS上的数据进行压缩,从而减少数据的存储空间,提高存储效率。但是,数据压缩也会增加数据访问的延迟和CPU的开销。
硬件升级:HDFS的性能也受硬件配置的影响。为了提高HDFS的性能,可以通过升级硬件来提高数据处理和存储的速度,如升级CPU、内存、硬盘和网络等硬件设备。
安全性
访问控制:HDFS支持基于ACL(访问控制列表)和基于POSIX权限的访问控制。管理员可以定义不同的用户和组的权限和访问控制列表,以限制文件和目录的访问权限。
数据加密:HDFS支持数据加密,可以对数据在传输和存储过程中进行加密保护,防止数据被窃取、篡改或泄露。
身份验证和授权:HDFS支持基于Kerberos的身份验证和授权,可以防止未经授权的用户访问HDFS。
安全日志记录:HDFS支持安全日志记录,可以记录用户的操作和事件,以便后续审计和调查。
MapReduce
MapReduce是一种分布式计算框架,用于处理大规模数据集。MapReduce将大规模数据集分成小块,然后分配给不同的计算节点进行并行处理,最后将结果合并为一个整体的结果。
主要组件
JobTracker:JobTracker是MapReduce框架的主节点,负责管理和监控整个任务的执行过程。它负责分配任务、监控任务的执行情况、处理任务失败和重试等。
TaskTracker:TaskTracker是MapReduce框架的工作节点,负责执行具体的任务。它接收JobTracker分配的任务,执行Map或Reduce任务,并向JobTracker汇报任务执行情况。
Mapper:Mapper是MapReduce框架的Map组件,负责将输入数据映射为键值对。它接收JobTracker分配的数据块,对每个数据块进行处理,并输出键值对。
Reducer:Reducer是MapReduce框架的Reduce组件,负责将Mapper输出的键值对按照键进行合并和处理。它接收JobTracker分配的Mapper输出的键值对,对相同键的值进行合并处理,并输出最终的结果。
Combiner:Combiner是MapReduce框架的可选组件,用于在Mapper和Reducer之间进行局部合并处理,减少数据的传输量和提高处理效率。
InputFormat:InputFormat是MapReduce框架的输入格式组件,负责将输入数据格式化为MapReduce框架可以处理的数据格式。
OutputFormat:OutputFormat是MapReduce框架的输出格式组件,负责将MapReduce框架的输出结果格式化为指定的输出格式。
基本原理
分布式计算:MapReduce框架可以将大规模数据集分成小块,然后分配给不同的计算节点进行处理,实现分布式计算,提高数据处理效率和并行性。
数据切分:MapReduce框架将大规模数据集切分成小块,以避免单节点处理大量数据造成的性能问题。
数据并行处理:MapReduce框架将小块数据分配给不同的计算节点进行并行处理,以提高数据处理效率和并行性。
数据合并:MapReduce框架将Map节点的输出数据按照键值进行分组,然后将同一个键值的数据发送给同一个Reduce节点进行处理,最终将结果合并为一个整体的结果。
应用场景
大数据处理:MapReduce适用于处理大规模数据集,可以将大规模数据集分成小块,然后分配给不同的计算节点进行并行处理,提高数据处理效率和并行性。
数据挖掘和分析:MapReduce可以对大规模数据集进行数据挖掘和分析,如用户行为分析、客户细分、推荐系统等。
搜索引擎:MapReduce可以用于对搜索引擎的网页索引进行分析和处理,如计算网页排名、处理查询请求等。
机器学习:MapReduce可以用于机器学习算法的实现和训练,如朴素贝叶斯分类、支持向量机等。
日志分析:MapReduce可以用于对大规模日志数据进行分析和处理,如网络日志、服务器日志等。
图像处理:MapReduce可以用于对大规模图像数据进行处理,如图像识别、图像分类等。
分布式爬虫:MapReduce可以用于实现分布式爬虫,从而加快爬虫的效率和速度。
数据流程
输入数据切分:MapReduce将输入数据切分成若干个小块,并将每个小块分配给不同的计算节点进行处理。
Map阶段:每个计算节点读取分配给它的小块数据,将数据处理成键值对的形式,并将键值对输出到本地磁盘上。
Combine阶段:可选的组件,用于在Map和Reduce之间进行局部合并处理,减少数据的传输量和提高处理效率。
Shuffle阶段:MapReduce框架将Map节点输出的键值对按照键进行排序和分组,然后将同一个键值的数据发送给同一个Reduce节点进行处理。
Reduce阶段:Reduce节点对接收到的键值对进行处理,将相同键值的数据进行合并处理,并输出最终的结果。
输出结果:MapReduce将Reduce节点处理的结果输出到指定的输出文件或数据存储系统中。
容错机制
任务重试机制:MapReduce框架会在任务执行失败时进行重试,直到任务成功执行或达到最大重试次数。在任务重试时,MapReduce框架会重新分配任务给其他节点执行,以避免某个节点出现故障导致任务执行失败。
数据备份机制:MapReduce框架会在每个节点上备份数据,以避免数据丢失或损坏。在任务执行过程中,如果某个节点出现故障导致数据丢失或损坏,MapReduce框架会从备份数据中恢复数据,然后重新分配任务给其他节点执行。
处理大量数据
数据切片:MapReduce框架会自动将输入数据切分成多个小块进行处理,从而实现分布式计算。可以通过调整切片大小来优化MapReduce程序的性能。
数据压缩:对于大规模的数据集,可以使用压缩算法对数据进行压缩,以减少数据传输和存储的开销,从而提高MapReduce程序的性能。
数据过滤:在MapReduce程序中,可以对输入数据进行过滤,只选择需要的数据进行处理,可以减少数据的处理量,从而提高程序的性能。
本地化缓存:MapReduce框架提供了本地化缓存功能,可以将一些常用的数据或计算结果缓存在本地,以减少网络传输和IO操作的开销,从而提高MapReduce程序的性能。
使用高性能硬件和网络:MapReduce程序的性能还受到硬件和网络的影响。因此,使用高性能的硬件和网络设备可以提高MapReduce程序的性能。
并行处理:MapReduce框架可以同时处理多个数据块,可以通过增加map和reduce任务的数量,来提高MapReduce程序的并行处理能力。
数据倾斜:在MapReduce程序中,数据倾斜可能会导致某些节点负载过重,从而影响整个程序的性能。因此,需要避免数据倾斜,可以采用数据分片、随机化等方法来平衡负载。
实现数据排序
Mapper阶段:在Mapper阶段,将输入数据按照需要排序的字段作为key,整个记录作为value进行映射。由于MapReduce默认是按照key值进行分组,因此可以保证在Reducer阶段输入的数据已经按照key值排序。
Reducer阶段:在Reducer阶段,按照输入的key值顺序对数据进行处理。可以使用一个计数器来记录当前的行号,然后将当前行号作为key,原始记录作为value进行输出。
设置排序选项:在MapReduce中,可以通过设置排序选项来指定排序的方式和排序的字段。可以使用JobConf类中的setOutputKeyComparatorClass()方法来设置排序的比较器。
设置分区选项:在MapReduce中,可以通过设置分区选项来确定数据分区的方式,从而保证数据在Reducer阶段按照key值有序。可以使用JobConf类中的setPartitionerClass()方法来设置分区器。
实现数据压缩
设置压缩选项:在MapReduce中,可以通过设置压缩选项来指定压缩的方式和压缩的格式。可以使用JobConf类中的setCompressMapOutput()和setOutputCompressorClass()方法来设置压缩选项。
Mapper阶段:在Mapper阶段,对输入数据进行压缩。可以使用压缩算法如Gzip、Snappy等对输入数据进行压缩,然后将压缩后的数据作为Mapper的输出。
Reducer阶段:在Reducer阶段,将Mapper输出的压缩数据进行解压缩,然后进行数据处理。
局限性
批处理模型:MapReduce采用批处理模型,无法实现实时数据处理和流式处理。
处理效率:由于MapReduce需要将数据写入磁盘,因此其处理速度相对较慢。与Spark等新型大数据处理框架相比,MapReduce的处理效率较低。
处理粒度:MapReduce的处理粒度比较粗,无法处理复杂的数据处理流程和算法。
编程模型:MapReduce采用基于Java的编程模型,需要编写较多的代码来完成任务。对于一些非Java开发人员来说,学习和使用MapReduce可能会有一定难度。
数据倾斜:在MapReduce程序中,数据倾斜可能会导致某些节点负载过重,从而影响整个程序的性能。
多个MapReduce任务之间的数据传输:在多个MapReduce任务之间需要进行数据传输,会增加数据传输和存储的开销,从而影响整个程序的性能。
优化性能
调整MapReduce的参数:可以通过调整MapReduce的参数来优化性能,如调整map和reduce任务的数量,调整输入和输出的格式等。
数据预处理:在MapReduce程序运行之前,可以对输入数据进行预处理,如对数据进行采样、过滤、格式转换等,以便更好地适应MapReduce程序的运行。
数据压缩:对于大规模的数据集,可以使用压缩算法对数据进行压缩,以减少数据传输和存储的开销,从而提高MapReduce程序的性能。
使用本地化缓存:MapReduce框架提供了本地化缓存功能,可以将一些常用的数据或计算结果缓存在本地,以减少网络传输和IO操作的开销,从而提高MapReduce程序的性能。
选择合适的数据结构和算法:在MapReduce程序中,选择合适的数据结构和算法可以大大提高程序的性能。例如,对于一些需要频繁访问的数据,可以使用哈希表来提高访问速度;对于一些计算密集型的任务,可以使用并行算法来提高计算速度。
避免数据倾斜:在MapReduce程序中,数据倾斜可能会导致某些节点负载过重,从而影响整个程序的性能。因此,需要避免数据倾斜,可以采用数据分片、随机化等方法来平衡负载。
使用高性能硬件和网络:MapReduce程序的性能还受到硬件和网络的影响。因此,使用高性能的硬件和网络设备可以提高MapReduce程序的性能。
和Spark的区别
处理模型:MapReduce采用批处理模型,每次处理一个数据集合,需要将数据先存储到HDFS中,然后进行处理。而Spark则采用内存计算模型,可以将数据存储在内存中,以加快处理速度,并支持实时数据处理。
处理效率:由于MapReduce需要将数据写入磁盘,因此其处理速度相对较慢。而Spark采用内存计算模型,处理速度更快。
处理范围:MapReduce适用于离线批处理的大规模数据处理,而Spark更适合于实时数据处理和流式处理。
编程模型:MapReduce采用基于Java的编程模型,需要编写较多的代码来完成任务。而Spark支持多种编程语言,包括Java、Scala、Python等,而且编程模型更加简洁。
生态系统:由于Spark较为新,因此其生态系统相对较小,而MapReduce生态系统更加完善,有更多的工具和应用程序可供选择。